The Death of the Monologue: How Voice AI Finally Learned “Social Intuition
Voice AI turn-taking modeling 2026 is solving AI’s missing social intuition. FinVolution’s competition and Mira Murati’s interaction models are teaching machines when to speak, when to say “mm-hm,” and when to stay silent.
URL Slug:
Introduction: The Missing Ingredient in Human-AI Conversation
Ask anyone who has used a voice assistant for more than a few minutes, and they will describe the same frustrations. The AI talks over you. It sits in silence long after you have finished speaking. It never says “mm-hm” to show it is listening. When you try to interrupt a mistake, it plows ahead regardless, locked into a robotic script it cannot deviate from.
For years, we have accepted these awkward interactions as inevitable. Voice AI, after all, is just software. It processes commands sequentially. It does not feel the rhythm of conversation. It certainly does not have intuition.
But 2026 is the year that changes.
Two major developments are converging to finally give voice AI what humans have possessed since infancy: social intuition. The first is a global competition challenging data scientists to model turn-taking in conversations. The second is the emergence of a new class of “interaction models” designed from the ground up for real-time, full-duplex communication.
This article explores how voice AI turn-taking modeling 2026 is solving the final barrier to making AI assistants feel like real people—and why the death of the robotic monologue is finally at hand.
Part 1: The Problem – Why Voice AI Feels Like a Bad Phone Call
1.1 The Turn-Taking Blind Spot
Imagine you are on the phone with someone who cannot hear your tone, cannot see your face, and cannot predict when you are about to speak. Every conversation would be a series of stumbles: both of you talking at once, followed by awkward silences, followed by apologies.
That is exactly how current voice AI works.

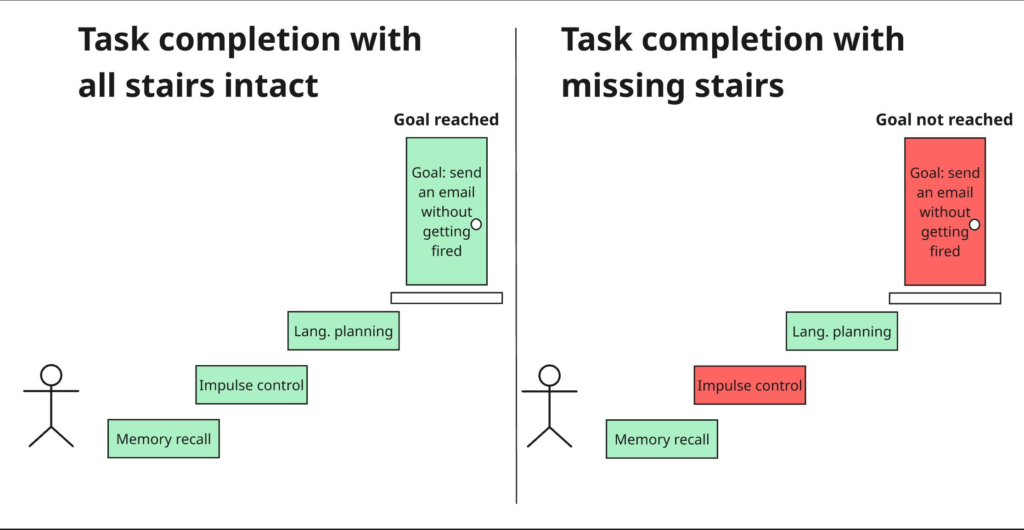
Traditional voice assistants process commands in a rigid sequence: the user speaks, the AI listens, the AI processes, the AI responds. There is no simultaneous processing. There is no ability to detect that a pause in your speech means “I’m thinking” rather than “I’m done.” There is no way to backchannel—to offer the small verbal nods (“mm-hm,” “uh-huh,” “I see”) that signal active listening in human conversation.
The result is what researchers call “turn-taking failure.” Without it, even the fastest model either talks over users or lets dialogue stall.
1.2 The Real-World Cost
This is not merely an annoyance. According to the τ-Voice benchmark, which evaluates voice agents on real customer-service tasks, production voice agents from OpenAI, Google, and xAI completed only 26% to 38% of tasks under realistic audio conditions with background noise, accented speech, and interruptions.
The benchmark found that 79% to 90% of failures traced to agent behavior rather than test artifacts. Agents struggled with authentication steps, sometimes claimed to complete tasks without executing them, and exhibited specific turn-taking failures: OpenAI’s model treated nearly every filler word as a new input, xAI’s model interrupted on 84% of turns, and Google’s model missed more than one in four user turns.
A voice assistant that sounds smooth but fails at real tasks is not an assistant. It is a demo.
Part 2: The Competition – FinVolution Tackles Turn-Taking
2.1 The 2026 Global AI Competition
On May 13, 2026, FinVolution Group launched its 11th Global Data Science Competition with a focused challenge: turn-taking modeling in conversations. The goal is to teach voice AI the social cues that humans perform instinctively—knowing when to take a turn, when to stay silent, and when a brief “mm-hm” is the right reply.
The competition provides participants with thirty seconds of dual-channel dialogue as context, challenging them to predict the speech events likely to occur in the next 800 milliseconds. The dataset is built from real dual-channel telephone conversations recorded across 35 regions of China, spanning a wide range of dialects and speaking styles.
As Tiezheng Li, CEO of FinVolution Group, explained: “Turn-taking is one of the open problems in voice interaction today. We hope what’s built here reaches far beyond research, letting millions of users experience more natural, more human conversation in everyday life” .
2.2 A Decade of AI Research
This is not FinVolution’s first foray into voice AI. The company has been running data science competitions for over a decade, attracting close to 10,000 participants from universities, research labs, and technology companies worldwide.
Past competitions have tackled deepfake detection, credit scoring, fraud detection, user behavior modeling, and dialect recognition. The 9th competition (2024) focused specifically on voice deepfake detection, with the winning team achieving a fake voice recognition rate of over 99% in the preliminary round.
The 2026 competition is supported by the China Computer Federation’s Technical Committee on Natural Language Processing, in collaboration with Fudan University’s Natural Language Processing Lab, and is an official partner competition of the 15th CCF International Conference on Natural Language Processing and Chinese Computing.
Part 3: The Breakthrough – Thinking Machines and “Full Duplex” AI
3.1 Interaction Models: A New Class of AI
While FinVolution’s competition focuses on turn-taking prediction, a more radical breakthrough arrived on May 11, 2026, from Thinking Machines Lab—the AI startup founded by former OpenAI CTO Mira Murati.
The company unveiled what it calls “interaction models” —a new class of AI designed from the ground up for real-time, multimodal collaboration rather than the familiar back-and-forth prompting we are used to with ChatGPT, Claude, or Gemini.
The key difference is full-duplex communication. Traditional AI chatbots, even in voice mode, still work on a turn-based system. You speak. The AI listens. The AI processes. The AI responds. There is a pause, however brief. Interaction models, by contrast, can listen and speak at the same time, just like humans during a phone call or face-to-face conversation.
3.2 How It Works: Micro-Turns and Time Awareness
The technical innovation lies in what Thinking Machines calls “time-aligned micro-turns.” Instead of waiting for the user to finish speaking, the model processes 200-millisecond chunks of audio and video input continuously while simultaneously generating its own output.
This architecture enables several conversational behaviors that current systems cannot achieve:
- Natural interruptions: The AI can jump in when you pause, correct itself, or react to visual cues without waiting for you to finish.
- Backchanneling: It can offer “mm-hm” and other verbal nods at precisely the right moment, signaling active listening.
- Time awareness: The model understands elapsed time and can proactively remind you of things at specific intervals.
- Simultaneous processing: It can translate speech in real time while you continue talking.
The system is split into two cooperating models: a fast interaction model that handles real-time perception and response, and a more powerful background model that runs deep reasoning, web searches, or complex tasks, feeding results naturally into the ongoing conversation.
3.3 The Benchmarks
Thinking Machines reports significant improvements over current systems on interactivity benchmarks:
| Metric | TML-Interaction-Small | GPT-Realtime-2 |
|---|---|---|
| Turn-taking latency | 0.40 seconds | 1.18 seconds |
| Voice conversation quality (FD-bench) | 77.8 | 46.8 |
| TimeSpeak (temporal prompting) | 64.7% | 4.3% |
| CueSpeak (responding to verbal cues) | 81.7% | 2.9% |
The model is not yet publicly available—it is currently in a limited research preview—but a wider release is planned for later in 2026.
Part 4: The Ecosystem – Who Else Is Racing to Natural Voice
4.1 OpenAI’s Real-Time Audio Model
OpenAI is reportedly developing a new real-time, bi-directional audio model designed to enable more natural voice interactions. Unlike traditional voice assistants that process commands sequentially, the proposed model would support continuous, two-way communication—meaning the AI could interrupt, clarify, or adjust its responses mid-conversation.
The model is expected to combine speech recognition, natural language understanding, and voice synthesis into a single unified system, reducing latency and eliminating the rigid turn-taking structure common in current voice interfaces.
4.2 The 2026 Voice AI Landscape
According to industry analysts tracking 2026 trends, several forces are converging to make voice AI the new operating system:
- Latency is nearly dead: With the shift to “native audio” voice-to-voice models, the three-second transcription lag is gone.
- Full duplex is the new standard: New architectures allow AI to listen while speaking, ending the robotic turn-taking era.
- Emotional intelligence is arriving: New models can detect sarcasm, stress, and hesitation in milliseconds, hearing not just words but mood.
- Apple’s “Super-Siri” is coming: Leaks suggest the iOS 26.4 update will finally bring LLM-powered Siri to 1 billion users.
Part 5: Why This Matters – The Social Intuition Threshold
5.1 Beyond Commands to Collaboration
The shift from turn-based to full-duplex interaction is not incremental. It is foundational.
Turn-based AI treats conversation as a series of transactions: query, response, query, response. Interaction models treat conversation as a shared, continuous activity where both participants are co-constructing meaning in real time.
This enables entirely new use cases. Imagine explaining a math problem while the AI draws diagrams on the fly. Imagine coding while it catches errors in real time without you asking. Imagine a cooking assistant that watches your camera and offers step-by-step help as you work.
5.2 The End of Prompt Engineering
Perhaps most significantly, interaction models may spell the end of prompt engineering as we know it. With turn-based AI, you have to batch your thoughts, phrase everything clearly upfront, and wait for the model to finish before you can correct, interrupt, or clarify.
With full-duplex AI, you can think out loud, change your mind mid-sentence, show your screen, or point at things—just like in a real conversation. The AI adapts to your pace and style instead of forcing you to adapt to its limitations.
5.3 The Benchmark That Still Matters
A note of caution: smooth conversation is not the same as task completion. The τ-Voice benchmark found that voice agents that sound natural can still fail at real customer-service tasks—mishearing confirmation codes, failing authentication steps, or claiming to complete database updates without actually doing so.
Thinking Machines’ interaction model has not yet been independently tested on τ-Voice. Its impressive FD-bench scores measure conversation quality, timing, and proactive engagement—not whether the conversation produced the right real-world outcome.
The test will come when these models are deployed in actual call centers, handling real customers with real problems.
Conclusion: The Monologue Dies, The Dialogue Begins
The voice AI turn-taking modeling 2026 movement represents the final barrier to making AI assistants feel like real people. FinVolution’s competition is tackling the prediction problem—teaching AI to anticipate when a user is about to speak. Thinking Machines’ interaction models are tackling the architectural problem—building AI that can listen and speak simultaneously.
Neither is complete. The competition’s results will not arrive until late July 2026. The interaction model is still in research preview. But the direction is clear.
Voice AI is learning to stop monologuing. It is learning to hear the small sounds—the “mm-hm,” the pause, the intake of breath—that carry as much meaning as words. It is learning to be a conversational partner rather than a command line.
The death of the monologue is the birth of actual dialogue. And that is a conversation worth having.
Frequently Asked Questions (FAQ)
What is turn-taking modeling in voice AI?
Turn-taking modeling is the task of teaching AI to predict when to speak, when to stay silent, and when to offer backchannel responses like “mm-hm.” It mimics the social intuition humans use to navigate conversations.
What is the FinVolution 2026 competition?
FinVolution’s 11th Global Data Science Competition challenges participants to predict speech events 800 milliseconds into the future using 30 seconds of dual-channel dialogue context. The prize pool is RMB 308,000 (approximately $42,900).
What is a “full duplex” AI?
Full duplex means the AI can listen and speak simultaneously, similar to a human phone conversation. Traditional AI uses “half duplex” communication—one party speaks, then the other responds.
Who is Thinking Machines Lab?
Thinking Machines Lab is an AI startup founded by Mira Murati, former CTO of OpenAI. In May 2026, the company unveiled “interaction models” designed for real-time, full-duplex voice and video conversation.
When will these technologies be available?
FinVolution’s competition concludes in late July 2026, with findings to be presented at NLPCC 2026. Thinking Machines’ interaction model is in research preview, with wider release planned for later in 2026.
Call to Action (CTA)
Have you experienced the frustration of being talked over by a voice assistant? Or tried a full-duplex AI like Gemini Live? Share your experiences in the comments below. And if you are a data scientist interested in the FinVolution competition, registration is open now.