The “Human-in-the-Loop” Model: Why Fully Autonomous AI is Often a Mistake
The “Human-in-the-Loop” Model: Discover why human-in-the-loop (HITL) AI outperforms fully autonomous systems in high-stakes applications. Learn about active learning, edge-case handling, and real-world failures of automation.
The Warning Signs Were Everywhere
The self-driving car cruised down a Phoenix highway at 70 miles per hour, navigating traffic flawlessly. Then, without warning, it swerved directly into a concrete barrier. The “disengagement” happened so fast that the human safety driver—there precisely for moments like this—had no time to react.
The NTSB later determined the car’s AI had encountered a scenario its training data never covered. There was no edge-case protocol. No human in the loop. Just a split second between smooth automation and catastrophic failure.
This is not an isolated incident. It is the central tension of artificial intelligence in 2026.
We are surrounded by headlines promising fully autonomous everything: self-driving fleets, AI lawyers that never sleep, medical diagnosis without doctors. The vision is seductive. Remove the human. Eliminate error. Scale infinitely.
But the reality is far messier. And increasingly, researchers, engineers, and regulators are reaching the same conclusion: fully autonomous AI is often a mistake.
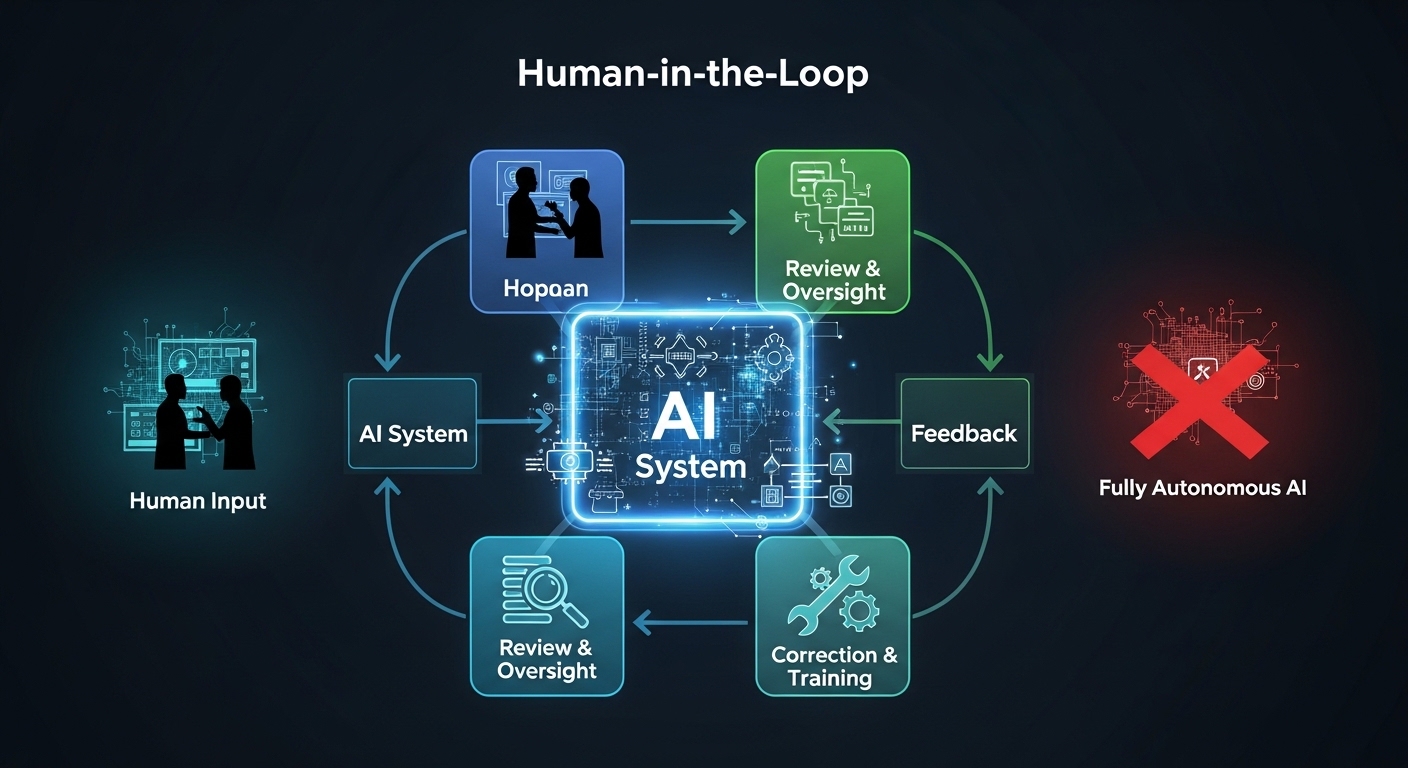
The alternative—the Human-in-the-Loop (HITL) model—is not a compromise. It is a strategic advantage. It is how you build systems that are safe, reliable, and continuously improving.
This guide explains what HITL means, why it outperforms full autonomy in high-stakes environments, and how to implement it effectively across legal, medical, automotive, and enterprise applications.
What Is Human-in-the-Loop?
Human-in-the-Loop (HITL) is an approach to AI system design where human judgment is intentionally integrated into the decision-making pipeline. The AI does not operate independently. Instead, it handles what it can confidently manage and escalates ambiguous, novel, or high-stakes cases to human experts .
This is not “AI with a backup.” It is a deliberate partnership where each party plays to its strengths:
| AI Strengths | Human Strengths |
|---|---|
| Process massive volumes of data | Apply common sense and context |
| Identify patterns humans would miss | Understand nuance and ambiguity |
| Execute repetitive tasks without fatigue | Handle novel edge cases |
| Scale across thousands of instances | Exercise ethical and legal judgment |
| Respond in milliseconds | Recognize when something “feels wrong” |
The most sophisticated HITL systems implement a concept called Active Learning. The AI is trained on a small set of labeled data, then identifies which unlabeled examples would be most valuable for a human to label next . The system explicitly queries the human for input on the cases it finds most uncertain—continuously improving while minimizing the human effort required.
The Case Against Full Autonomy
Why is full autonomy often a mistake? The evidence spans industries.
The Long Tail of Edge Cases
AI systems excel at the “happy path”—the 99% of cases that look like their training data. They fail catastrophically on the 1% that does not.
Self-driving vehicles have logged millions of miles, yet every significant accident involves a scenario the training data never covered: an overturned truck painted to look like sky, a pedestrian carrying a large mirror, construction signage that deviates from standard patterns .
For LLMs applied to legal discovery, the same principle holds. Standard contract clauses are handled easily. A novel indemnification provision with contradictory cross-references? The AI might miss the conflict entirely—or “hallucinate” a resolution that does not exist .
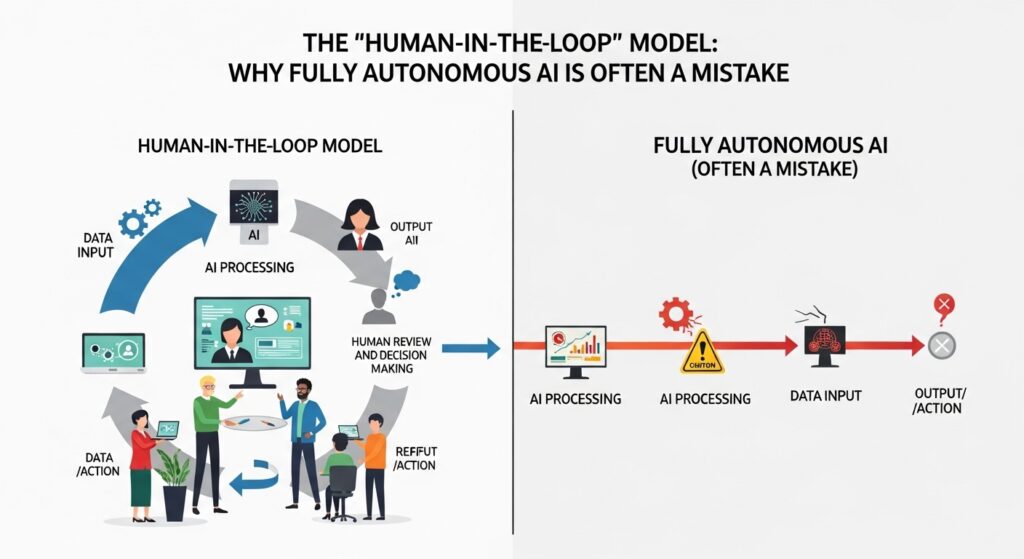
The problem is mathematical. The space of possible real-world scenarios is infinitely larger than any training dataset. Full autonomy assumes the training data covers everything that matters. It never does.
Brittleness Under Distribution Shift
Models are trained on historical data. The world changes. When the distribution of inputs shifts—new regulations, novel legal precedents, unexpected weather patterns—models degrade silently .
A legal AI trained on pre-2024 case law might miss the implications of a new Supreme Court ruling. A medical AI trained on pre-pandemic data might misinterpret post-COVID symptoms. Full autonomy offers no graceful degradation. It just fails.
The Transparency Paradox
When a fully autonomous system makes a mistake, explaining why is often impossible. The model’s decision is buried in billions of parameters. There is no chain of reasoning to audit .
For high-stakes decisions—medical diagnoses, loan approvals, bail determinations—this is unacceptable. Regulators demand explainability. Patients demand accountability. Courts demand due process. Full autonomy delivers none of these.
The HITL Difference: Real-World Results
The superiority of HITL is not theoretical. It is measurable.
Legal Discovery: From 99% to 100%
Consider document review in litigation. An AI can process 10,000 documents and correctly identify 9,900 as non-responsive. That is 99% accuracy—impressive by any measure.
But 100 documents remain. Some contain privileged information that must be protected. Others are responsive to the opposing party’s request. And a few are completely novel—document types the AI has never seen.
A fully autonomous system would either produce the 100 documents blindly (risking privilege waiver) or withhold them (risking sanctions). A HITL system routes those 100 documents to a human reviewer. The human spends 30 minutes on what would have taken days without AI—and the result is legally defensible .
The firms reporting 63% faster document review are not running fully autonomous AI. They are running HITL systems where AI handles the bulk and humans handle the exceptions .
Medical Imaging: Sensitivity vs. Specificity
Radiology AI can achieve 96% sensitivity for detecting lung nodules. That means it misses 4% of cancers. For a fully autonomous system, those 4% of patients receive false negatives.
With HITL, the AI flags suspicious areas and presents them to a radiologist. The radiologist reviews only the flagged cases—a fraction of the total—applies clinical judgment, and catches most of the AI’s misses. The result is super-human performance: the speed of AI combined with the nuance of human expertise .
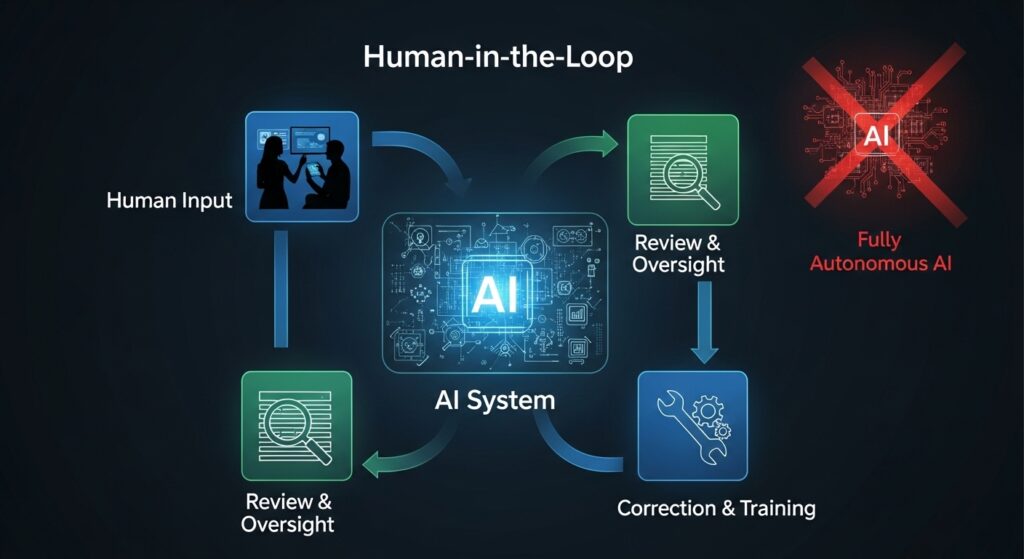
Autonomous Vehicles: The Disengagement Metric
Every autonomous vehicle system has a “disengagement rate”—how often the human safety driver must take control. Companies pursuing full autonomy treat disengagements as failures to be eliminated.
HITL proponents see them differently. Disengagements are learning opportunities. Each human takeover is a data point about a scenario the AI could not handle. Those scenarios are added to the training set. The model improves. The disengagement rate drops over time—not because the AI hides its uncertainty, but because it genuinely learns .
Implementing HITL: A Technical Framework
Moving from concept to implementation requires intentional architecture. Here is how HITL works in practice.
Confidence Thresholding
The most common HITL pattern is confidence-based escalation. The AI produces both a prediction and a confidence score. If confidence exceeds a threshold (e.g., 95%), the AI acts autonomously. If confidence falls below the threshold, the system escalates to a human .
Example: An AI reviewing medical records for relevant billing codes. Standard codes (99213, 99214) are high-confidence. An unusual combination of modifiers drops confidence to 60%—escalated to a human coder.
Active Learning Query Strategies
For systems that improve over time, the AI should not escalate randomly. It should escalate the examples that will be most valuable for human labeling .
Common query strategies include:
| Strategy | Description |
|---|---|
| Uncertainty Sampling | Escalate examples the model is least certain about |
| Query-by-Committee | Run multiple models; escalate where they disagree |
| Expected Model Change | Escalate examples likely to change the model most |
| Diversity Sampling | Escalate examples representing novel patterns |
The goal is to minimize the number of human labels required to achieve a given performance level. Active learning can reduce labeling requirements by 80-90% compared to random sampling .
Human Workflow Integration
The technical system is only half the solution. HITL requires careful attention to human workflows :
- Prioritization: Escalated cases should be presented in order of urgency or importance
- Context: Humans need sufficient context to make decisions (what the AI saw, what it considered, why it was uncertain)
- Feedback Loop: Human decisions must be captured and fed back into model retraining
- UI/UX: The interface for human review should be optimized for speed and accuracy, not generic
The HITL Spectrum: When Is Full Autonomy Acceptable?
Not every application requires human oversight. The appropriate level of autonomy depends on three factors:
| Factor | Low Risk → High Risk |
|---|---|
| Stakes of Error | Low (movie recommendations) → High (medical diagnosis) |
| Novelty of Inputs | Static (form processing) → Dynamic (autonomous driving) |
| Explainability Required | None (content moderation) → Full (legal decisions) |
Low-stakes, static, low-explainability applications can tolerate full autonomy. Recommending a movie you might not like is fine. Automatically sorting email into folders is fine.
High-stakes, dynamic, high-explainability applications require HITL. Medical diagnosis. Legal discovery. Autonomous vehicles. Loan approvals. Bail decisions.
The mistake is treating all applications the same. Full autonomy is a tool for specific contexts. HITL is the default for everything else.
Real-World HITL Implementations
Relativity: AI + Human Review for eDiscovery
Relativity (formerly Relativity aiR) is a generative AI solution for eDiscovery that explicitly implements HITL . The AI reviews documents, but the platform:
- Shows the AI’s reasoning (which documents it considered, why it reached its conclusion)
- Enables human review of AI-identified documents
- Supports privilege log creation with human oversight
- Maintains audit trails for defensibility
The result is not faster at the expense of accuracy. It is faster and legally defensible because the human remains in control of consequential decisions .
Blue J: AI-Powered Legal Prediction with Expert Vetting
Blue J uses AI to predict legal outcomes based on case law. But critically, the platform does not just output predictions. It shows users the precedents the AI relied on, explains its reasoning, and allows legal experts to override or adjust predictions based on factors the AI cannot capture—client-specific nuances, unpublished rulings, or emerging trends not yet reflected in the database .
Scale AI: Human Labeling for Autonomous Systems
Scale AI has built a business around the insight that even the most sophisticated AI requires human-labeled training data. Their platform combines automated pre-labeling with human review, enabling customers to build high-quality datasets at scale .
For autonomous vehicle companies, Scale provides tools to label millions of images—but every critical edge case is reviewed by a human. The AI improves. The humans focus on what matters.
Common HITL Mistakes (And How to Avoid Them)
Mistake 1: The “Human as Afterthought” Trap
Many systems treat human review as a compliance checkbox—added after the AI is built, with poor UI, no prioritization, and no feedback loop. The result is slow, frustrating, and low-quality human input.
Solution: Design the human interface first. Build the AI to serve the human reviewer, not the other way around.
Mistake 2: Escalating Everything
Some HITL systems escalate so many cases that humans are overwhelmed. The AI provides no value; it is just an inefficient routing layer.
Solution: Tune confidence thresholds. Use active learning to escalate only the most valuable cases. Measure human workload as a key metric.
Mistake 3: No Feedback Loop
Human decisions are captured but never used to improve the model. The AI remains static; humans keep handling the same edge cases forever.
Solution: Implement continuous learning. Human decisions should become training data for the next model version. The system should improve measurably over time.
Mistake 4: Ignoring Human Factors
Humans get tired, bored, and inconsistent. A HITL system that expects perfect human performance at 3 AM is doomed.
Solution: Design for human limitations. Limit session lengths. Provide clear guidelines. Use multiple reviewers for high-stakes decisions. Measure inter-rater reliability.
The Future: From HITL to Human-in-the-Command
The terminology is evolving. “Human-in-the-loop” suggests a human stuck in a loop—tending to an AI that is mostly autonomous. The next paradigm is Human-in-the-Command : the human as supervisor of a swarm of AI agents, each handling specific sub-tasks, with the human making strategic decisions about which agents to deploy, when to override them, and how to integrate their outputs .
In this model:
- AI agents are specialized, not general
- Humans set goals and constraints
- Agents propose actions; humans approve or modify
- Humans handle exceptions and edge cases
- Agents learn from human feedback continuously
This is not autonomy with a backup. It is augmented intelligence—AI and humans doing what each does best, in a tight feedback loop, achieving outcomes neither could alone.
When Full Autonomy Actually Works
A balanced view acknowledges that full autonomy has its place. The conditions are narrow but real:
Massive scale, low stakes. Spam filtering processes billions of emails. A false positive (legitimate email flagged as spam) is annoying. A false negative (spam in inbox) is also annoying. No one dies. Full autonomy is fine.
Fully observable, static environments. Chess is a closed system with perfect information. Stockfish plays superhuman chess autonomously. The board does not change mid-game in unexpected ways.
Closed-loop systems with immediate feedback. Thermostats maintain temperature autonomously. If the temperature overshoots, the system corrects immediately. There is no long tail of edge cases that matter.
Outside these narrow conditions, HITL is not a compromise. It is the only responsible approach.
Getting Started with HITL
For organizations adopting AI, the path is clear:
Step 1: Audit your use cases. For each AI application, assess stakes, novelty, and explainability requirements. Flag high-risk applications for HITL.
Step 2: Design the human interface first. Before writing a line of AI code, design how humans will review, override, and provide feedback. Build for their workflow, not yours.
Step 3: Implement confidence thresholds. Start conservative (escalate anything below 90% confidence). Measure. Adjust.
Step 4: Build the feedback loop. Every human decision should become training data. Retrain models regularly. Measure improvement.
Step 5: Measure the right metrics. Not just AI accuracy. Human workload. Escalation rate. Time-to-resolution. User satisfaction. System improvement over time.
Frequently Asked Questions
Q: Does HITL mean AI is not ready for prime time?
A: No. It means AI is ready to augment human work, not replace it. The most successful AI deployments in law, medicine, and finance are all HITL.
Q: Doesn’t HITL defeat the purpose of automation?
A: Only if your purpose is removing humans entirely. For most organizations, the purpose is better outcomes, faster. HITL delivers that.
Q: How much human time does HITL actually require?
A: In legal discovery, firms report reducing document review time by 63% . In medical imaging, radiologists reviewing AI-flagged cases spend a fraction of the time of full manual review. HITL is not “AI with a human doing all the work.” It is AI doing most of the work, humans doing the critical part.
Q: Can HITL systems ever become fully autonomous?
A: Possibly, as they handle more edge cases and confidence increases. But the threshold for removing the human should be extremely high in high-stakes applications. Many organizations keep the human in the loop permanently—not because the AI cannot handle the cases, but because accountability and explainability require human oversight.
Q: What about cost? Doesn’t HITL require expensive human experts?
A: Yes, but far fewer of them. A HITL system might require one human reviewer where full manual review required ten. The cost savings are substantial—and the quality is higher.




