How Large Language Models Work: An Easy Guide to Neural Networks and Transformers
How Large Language Models Work: An Easy Guide to Neural Networks and Transformers, In 2026, large language models (LLMs) like ChatGPT, Gemini, and Claude have become as integral to daily life as search engines were a decade ago. We ask them to write emails, debug code, summarize documents, and even offer relationship advice. Yet for most users, these systems remain magical black boxes—impressive but utterly mysterious.
How does a machine, fundamentally a collection of silicon switches, learn to understand language, reason about complex problems, and generate human-like text?
This guide demystifies large language models without requiring a computer science degree. We’ll explore the building blocks—neural networks, the revolutionary transformer architecture, and the massive training process that turns raw text into something that feels remarkably like understanding.

The Core Insight: Language as Math
Before we dive into architecture, let’s start with the fundamental insight that makes everything possible.
A large language model is, at its core, a mathematical function. It takes numbers as input and outputs numbers. Language enters the system only at the boundaries—converted to numbers on the way in, converted back to words on the way out.
Think of it like this: You don’t need to understand French to translate a French novel. You need a French-English dictionary and a grammar guide. Similarly, a language model doesn’t need to “understand” language in the human sense. It needs a way to convert words to numbers, a mathematical structure that captures relationships between those numbers, and massive amounts of text to learn from.
This mathematical approach has proven extraordinarily effective. But to understand why, we need to understand the building blocks.
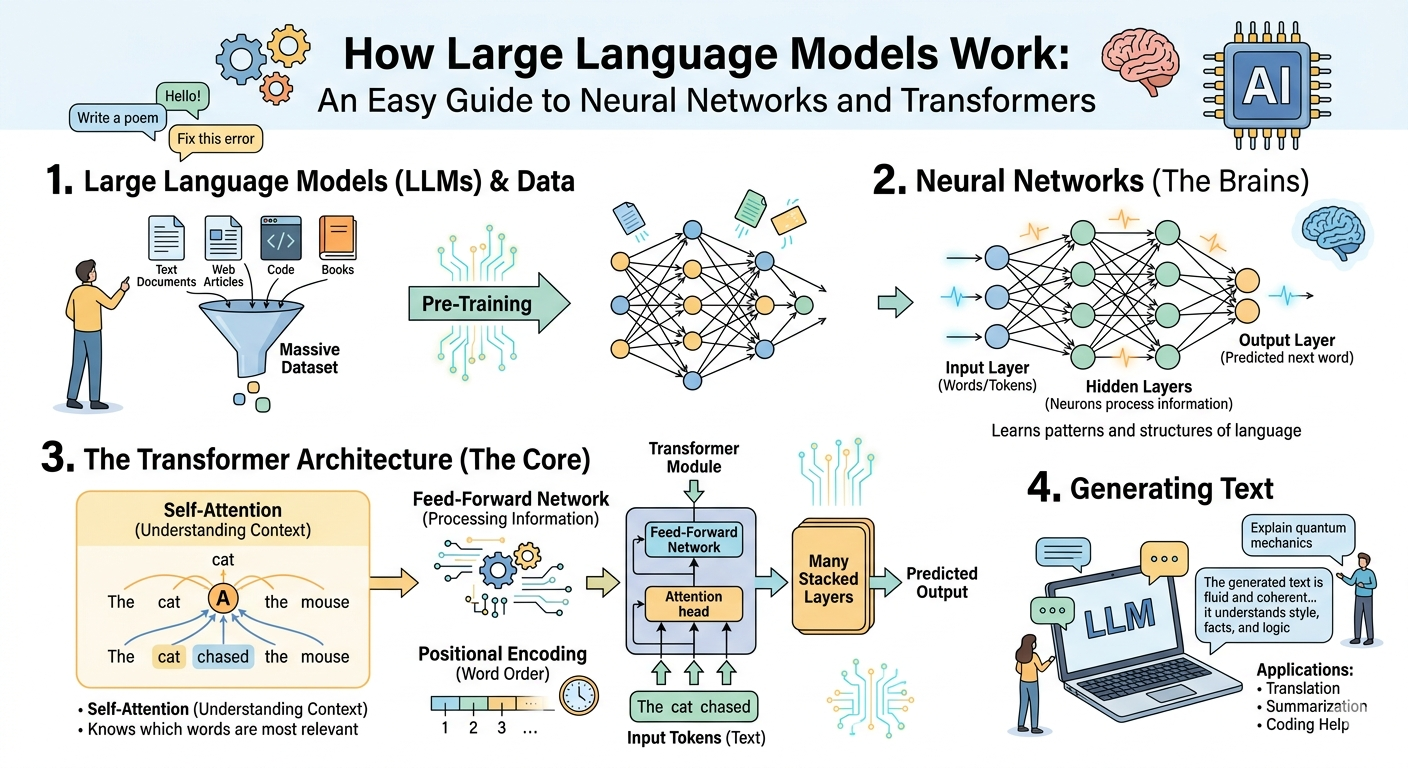
Part 1: Neural Networks—The Brain-Inspired Foundation
What Is a Neural Network?
A neural network is a computational system loosely inspired by the human brain. Just as your brain consists of billions of interconnected neurons (nerve cells), an artificial neural network consists of interconnected nodes (often called “neurons”) organized in layers.
The Basic Structure:
Input Layer → Hidden Layer(s) → Output Layer- Input Layer: Receives the raw data (in our case, numbers representing words)
- Hidden Layers: Where the actual computation happens. Most modern LLMs have dozens or hundreds of hidden layers.
- Output Layer: Produces the final result (numbers representing the next word)
Each connection between neurons has a weight—a number that determines how much influence one neuron has on another. Learning, in neural networks, is the process of adjusting these weights based on examples.
How a Neuron Works
A single artificial neuron is a simple mathematical operation:
- Receive inputs: Numbers from previous neurons
- Multiply each input by its weight: Some inputs matter more than others
- Sum everything together: Add up all the weighted inputs
- Apply an activation function: A mathematical operation that determines whether the neuron “fires”
The activation function introduces non-linearity. Without it, a stack of neurons would just be a complicated linear equation—no more powerful than a simple straight line. Non-linearity allows neural networks to learn complex patterns.
Learning: The Backpropagation Revolution
How do neural networks learn? Through a process called backpropagation (short for “backward propagation of errors”).
Imagine teaching a child to throw a ball into a basket:
- The child tries (makes a prediction)
- You measure how far the ball landed from the basket (calculate the error)
- You give feedback: “Aim more to the left” (propagate the error backward)
- The child adjusts their aim (update weights)
- Repeat thousands of times
Backpropagation does the same thing mathematically:
- Forward pass: Input flows through the network to produce a prediction
- Error calculation: Compare prediction to the correct answer
- Backward pass: Calculate how much each weight contributed to the error
- Weight update: Adjust weights slightly to reduce future error
- Repeat: Millions or billions of times
Through this process, the network gradually discovers patterns in the training data.
Part 2: From Simple Networks to Transformers
Early neural networks worked well for simple tasks like recognizing handwritten digits. But they failed at language. The problem? Sequences.
Language is inherently sequential. The meaning of a word depends on the words before it, after it, and sometimes both. A network that processes each word in isolation misses everything that makes language meaningful.
Recurrent Neural Networks (RNNs): The First Attempt
Recurrent Neural Networks were designed to handle sequences. They process one word at a time, maintaining a “memory” (called a hidden state) that carries information forward.
How RNNs Work:
- Process the first word → update memory
- Process the second word → update memory
- Continue through the entire sequence
- Use the final memory to make predictions
The Problem: RNNs suffer from what researchers call the “vanishing gradient problem.” When you backpropagate error through a long sequence, the signal becomes so diluted that the network can’t learn relationships between words that are far apart.
If you have a 500-word document, an RNN struggles to connect a pronoun in sentence 20 to its referent in sentence 3. The memory simply isn’t strong enough over long distances.
The Transformer: A Revolutionary Architecture
In 2017, a team at Google Brain published a paper titled “Attention Is All You Need.” It introduced the transformer architecture, and nothing has been the same since.
The transformer solved the long-distance dependency problem with a mechanism called self-attention. Instead of processing sequentially, transformers process all words in parallel while allowing each word to “look at” every other word in the sequence.
Part 3: The Transformer Architecture Explained
Let’s build a transformer piece by piece. Don’t worry if every detail doesn’t stick—focus on the intuition behind each component.
Tokenization: Turning Words into Numbers
Before a transformer can process text, it needs to convert words into numbers. This happens through tokenization.
A token is a chunk of text—a word, part of a word, or a punctuation mark. For example:
- “ChatGPT is amazing” might become: [“Chat”, “G”, “PT”, ” is”, ” amazing”]
- Each token gets a unique ID number (like 5234, 127, 8902, etc.)
These IDs are then converted into embeddings—vectors (lists of numbers) that capture meaning. Here’s the crucial insight: Words with similar meanings have similar embedding vectors.
In the embedding space:
- “king” and “queen” are close together
- “apple” and “orange” are close together
- “king” and “apple” are far apart
These embeddings aren’t hand-coded. The model learns them during training.
Positional Encoding: Preserving Order
Transformers process all tokens in parallel, which is efficient but creates a problem: how does the model know word order? “Dog bites man” and “Man bites dog” use the same words but mean opposite things.
Positional encoding solves this. Before feeding the embeddings into the transformer, the model adds a unique signal to each token’s embedding based on its position. This signal is mathematically constructed so the model can learn to recognize positions.
Think of it like adding coordinates to each word. The model sees not just “king” but “king at position 1,” then “queen at position 2,” etc.
Self-Attention: The Magic Mechanism
Self-attention is the transformer’s signature innovation. It allows each token to gather information from all other tokens in the sequence.
The Intuition:
Imagine you’re reading a sentence: “The animal didn’t cross the road because it was tired.”
When you read “it,” you know it refers to “animal,” not “road.” How? You attended to the relevant context. Self-attention does the same thing mathematically.
How It Works (Simplified):
For each token, the model creates three vectors:
- Query: What is this token looking for?
- Key: What does this token offer to others?
- Value: What information does this token actually provide?
The attention score between token A and token B is calculated by comparing A’s Query with B’s Key. A high score means B is relevant to A’s context. The model then aggregates the Values of relevant tokens, weighted by these scores.
In practice, transformers use multi-head attention—multiple attention mechanisms running in parallel, each focusing on different types of relationships (syntax, semantics, co-reference, etc.).
Feed-Forward Networks: Adding Depth
After attention, each token’s representation passes through a feed-forward network—a small neural network that processes each token independently. This adds computational depth and allows the model to transform the attended information into richer representations.
Layer Normalization and Residual Connections
Two technical innovations make training very deep transformers possible:
Residual Connections: Instead of replacing the input, each sub-layer (attention or feed-forward) adds its output to the input. This creates a “highway” for gradients during training, allowing the model to learn effectively even with hundreds of layers.
Layer Normalization: A technique that stabilizes training by normalizing the values flowing through the network, preventing them from becoming too large or too small.
The Stack: Building Depth
A complete transformer stacks multiple layers of this architecture:
- Layer 1: Self-attention + Feed-forward
- Layer 2: Self-attention + Feed-forward
- …
- Layer 96: Self-attention + Feed-forward (for models like GPT-5)
Each layer builds on the previous one, allowing the model to learn increasingly abstract representations. Lower layers might learn grammar and syntax. Middle layers might learn semantic relationships. Top layers might learn high-level reasoning patterns.
Decoder-Only Architecture: How GPT Works
While the original transformer had both an encoder (to read input) and a decoder (to generate output), modern LLMs like GPT use a decoder-only architecture with a crucial modification: causal masking.
Causal masking ensures that when predicting the next word, the model can only attend to previous words, not future ones. This makes generation possible—the model predicts one word at a time, using all previously generated words as context.
Generation Process:
- Input: “The capital of France is”
- Model predicts: “Paris”
- New input: “The capital of France is Paris”
- Model predicts: “.”
- Continue until stop condition
This autoregressive generation—predicting one token, adding it to context, predicting the next—is how all decoder-only LLMs produce text.
Part 4: Training—From Random Weights to Language Mastery
A freshly initialized transformer with random weights produces gibberish. The journey from random to fluent happens through massive-scale training.
Pre-Training: Learning from All the Text
The first stage is pre-training. The model consumes enormous amounts of text—essentially the public internet, books, academic papers, code repositories—and learns to predict the next token.
Training Objective: Next Token Prediction
Given a sequence of tokens, predict the next token. That’s it. There’s no labeled data, no explicit grammar lessons, no human teaching. The model learns from the inherent structure of language itself.
If you’ve seen “The quick brown fox jumps over the lazy,” the next token should be “dog.” If you’ve seen “def fibonacci(n): if n <= 1: return n,” the next tokens should be “else: return fibonacci(n-1) + fibonacci(n-2).”
Through this simple objective, the model learns:
- Grammar: To predict correctly, it must learn noun-verb agreement, tense, and sentence structure
- Semantics: It learns that “king” and “queen” are related, that “Paris” is associated with “France”
- Reasoning: To predict the end of a chain of reasoning, it must learn to reason
- Code: Programming languages follow strict patterns; predicting the next token means learning those patterns
Scale: The Three Factors
Model performance scales predictably with three factors:
- Model Size: More parameters (the weights in the network) = more capacity
- Data Size: More training tokens = more patterns to learn
- Compute: More training compute = more optimization steps
Modern frontier models like GPT-5, Gemini 3 Pro, and Claude 4 are trained on trillions of tokens using hundreds of billions of parameters on hundreds of millions of dollars of compute.
Fine-Tuning: Teaching Specific Skills
A pre-trained model is a generalist. It can complete sentences but isn’t yet a helpful assistant. Fine-tuning adapts the model to specific tasks or behaviors.
Supervised Fine-Tuning (SFT): Train the model on human-written examples of desired behavior. For a chatbot, this means showing it thousands of examples of helpful, harmless, honest conversations.
Reinforcement Learning from Human Feedback (RLHF): Humans rank multiple model outputs, and a reward model learns to predict which outputs humans prefer. The language model then optimizes to maximize this reward.
This two-stage process—pre-training for broad knowledge, fine-tuning for alignment—produces models that are both capable and (ideally) safe.
Part 5: What’s Actually Happening Inside
Now that we understand the architecture, let’s peek inside a working model.
The Prediction Process
When you type a prompt into ChatGPT or Gemini, here’s what happens:
- Tokenization: Your prompt is broken into tokens and converted to IDs
- Embedding: Each token ID is converted to an embedding vector
- Positional Encoding: Position signals are added
- Transformer Layers: The embeddings flow through 50-100 layers of attention and feed-forward networks
- Output Projection: The final representations are converted to probabilities over the token vocabulary (50,000 to 200,000 possible tokens)
- Sampling: The model selects a token based on these probabilities (not always the most likely—temperature controls randomness)
- Iteration: The new token is added to the input, and the process repeats
All of this happens in milliseconds to seconds, depending on model size and hardware.
What the Model “Knows”
It’s important to understand what the model does and doesn’t have:
The Model Has:
- Statistical patterns learned from training data
- Representations of concepts and relationships
- The ability to combine patterns in novel ways
- A “world model” derived from text (flawed and incomplete)
The Model Does Not Have:
- A database of facts to look up (no search)
- True understanding or consciousness
- The ability to reason about things outside its training distribution
- Any mechanism for truth verification
When a model answers a question, it’s not retrieving a fact from memory. It’s generating a sequence that matches patterns learned during training. That sequence may be factually correct (if the pattern appears often in training) or completely fabricated (if the pattern is rare or absent).
This is why models hallucinate. They’re not lying—they’re generating what’s statistically plausible based on patterns, with no mechanism for fact-checking.
Part 6: Beyond Text—Multimodal Models
In 2026, the most advanced models are no longer limited to text. Models like Google Gemini 3, GPT-5, and Claude 4 are multimodal—they can process images, audio, and video alongside text.
How Multimodality Works
Multimodal models use the same transformer architecture but with additional encoders for other modalities:
- Vision Encoder: Converts images to sequences of patches, each patch becomes an embedding similar to text tokens
- Audio Encoder: Converts audio to spectrograms, then to embeddings
- Video Encoder: Treats video as sequences of frames, each frame as images
These modality-specific embeddings are fed into the same transformer layers, allowing cross-modal attention. The model can look at an image and read text about it, understanding how they relate.
Example: You upload a photo of a plant with brown spots and ask, “What’s wrong with my plant?” The model:
- Encodes the image into patch embeddings
- Encodes your text prompt into token embeddings
- Processes them together through transformer layers
- Attends from “brown spots” to relevant patches in the image
- Generates a response based on plant disease patterns learned from training
This integration of modalities enables entirely new capabilities—from analyzing medical images to understanding complex diagrams to generating images from descriptions.
Part 7: Limitations and Challenges
Understanding how LLMs work also means understanding their limitations.
Hallucination
As mentioned, models generate plausible text, not verified facts. They have no internal truth meter. Hallucination is not a bug that can be fixed—it’s a feature of how autoregressive generation works.
Mitigations: Retrieval-augmented generation (RAG) gives models access to external knowledge bases. Reinforcement learning reduces but doesn’t eliminate hallucinations. But no current model is hallucination-free.
Reasoning Limitations
Models can appear to reason, but they’re pattern-matching. For problems well-represented in training data, they perform brilliantly. For novel problems requiring genuine reasoning, they often fail in ways humans wouldn’t.
Example: Simple arithmetic is trivial for models trained on billions of math problems. But multi-step reasoning requiring planning, backtracking, and verification remains challenging.
Context Window Constraints
Even with million-token context windows, models have finite attention. They can’t maintain perfect recall over arbitrarily long documents. The effective context—what the model actually uses—is often much smaller than the theoretical maximum.
Computational Cost
Inference (generating responses) requires significant compute. Every token generated requires a full forward pass through the entire network. This is why models have rate limits and why large context windows are expensive.
Part 8: The Future—What’s Next?
As of 2026, the transformer architecture remains dominant, but researchers are actively exploring what comes next.
Test-Time Compute
Instead of making models bigger, frontier models now invest compute at inference time. A model might “think” for seconds or minutes on complex problems, exploring multiple solution paths before answering. This approach—sometimes called “chain of thought” or “agentic reasoning”—enables capabilities that raw scale alone cannot achieve.
Mixture of Experts (MoE)
Instead of activating all parameters for every token, MoE models have specialized “expert” sub-networks and route tokens to relevant experts. This allows models to have enormous parameter counts (trillions) while keeping inference costs manageable.
Beyond Transformers
Researchers are actively exploring alternatives to the transformer architecture:
- State Space Models (SSMs): Like Mamba, aiming for linear scaling with sequence length
- Recurrent Memory Transformers: Combining recurrence with attention for infinite context
- Liquid Neural Networks: Inspired by biological neurons, potentially more efficient
None have yet displaced transformers at the frontier, but the landscape is evolving rapidly.
Conclusion: Understanding the Magic
Large language models are simultaneously simpler and more complex than they appear.
Simpler because, at their core, they’re just mathematical functions trained to predict the next token. There’s no secret sauce, no hidden consciousness, no magic. Just neural networks, transformers, and massive amounts of data.
More complex because the patterns that emerge from this simple objective are extraordinary. Grammar, reasoning, code generation, translation, summarization—all arise from learning to predict what comes next.
Understanding how LLMs work doesn’t diminish their magic. If anything, it deepens the wonder. A system built from simple mathematical operations, scaled to trillions of parameters and trained on the accumulated text of human civilization, can converse, create, and reason in ways that were science fiction a decade ago.
The transformer architecture that made this possible was published in 2017. We are still in the early days of understanding what these systems can do—and what we should do with them.
The math is beautiful. The implications are profound. And the journey has only just begun.





