Cinematic AI Video: A Guide to Narrative Consistency in Sora 2.0
Cinematic AI Video: A Guide to Narrative Consistency in Sora 2.0, Master narrative consistency in Sora 2.0 with advanced prompt engineering techniques. Learn how to leverage long-context capabilities, style spines, and image-to-video workflows for professional cinematic results.
The Ultimate AI Director’s Challenge
You have a vision. A sweeping wide shot of a medieval castle at dawn. A slow dolly into the throne room. A close-up of the queen’s weathered hands gripping a goblet. A reaction shot of the court gasping.
In traditional filmmaking, this sequence would require a director, a cinematographer, a production designer, a costume department, and weeks of planning. The consistency of lighting, character appearance, camera language, and spatial logic would be maintained by a crew of dozens.
In Sora 2.0, you have only your prompt and your patience.
The gap between generating a single impressive shot and telling a coherent story has been the defining challenge of AI video. Sora 1.0 was “solid for single-shot realism, but weak when it comes to coherence” . Characters changed appearance between cuts. Lighting shifted arbitrarily. Camera angles felt random. The model treated each generation as an isolated moment rather than a thread in a larger narrative tapestry .
Sora 2.0 changes everything.
With expanded long-context memory, cinematography-specific training, physics-aware generation, synchronized audio, and the new Storyboard feature, Sora 2.0 has become the first AI video model capable of genuine narrative consistency . This guide draws on OpenAI’s official prompting cookbook, technical analysis of Sora 2’s architecture, and community best practices to help you master the art of consistent AI storytelling.
The Architecture of Consistency: How Sora 2.0 Thinks
Before diving into prompting techniques, it is essential to understand what changed under the hood. Sora 2.0’s ability to maintain narrative consistency stems from two key architectural upgrades.
Long-Context Capability: The Memory Upgrade
Sora 1.0 learned from single clips. It had no memory of what came before. Each generation was a fresh start.
Sora 2.0 introduces an expanded memory window that lets it “remember” previous shots. This is built on 2025’s LCT (Long Context Tuning) research, which fundamentally changed how the model processes sequences .
What this means in practice: If you generate a video of a chef cooking, the same apron and kitchen background stay consistent across close-up and wide shots. The model understands that the chef in the wide shot and the chef in the close-up are the same entity .
Critically, this memory operates across multiple generations when you use the Storyboard feature. By creating all your videos using the same storyboard, your characters remain consistent across cuts . The storyboard acts as a persistent memory container, anchoring each new generation to the established world state.
Cinematography Learning: The Director’s Education
Sora 2.0 was trained on millions of film clips using “Cut2Next-like methods” to understand shot transitions. It has learned the grammar of visual storytelling—how a pan naturally flows into a zoom, how a reaction shot follows an action, how to shift from a character’s smiling face to a view of their entire graduation ceremony without disorienting the viewer .
This training means Sora 2.0 understands film language innately. When you ask for a “wide establishing shot” followed by a “medium close-up,” the model knows the spatial relationship between those framings. It knows the wide shot establishes geography; the close-up explores emotion .
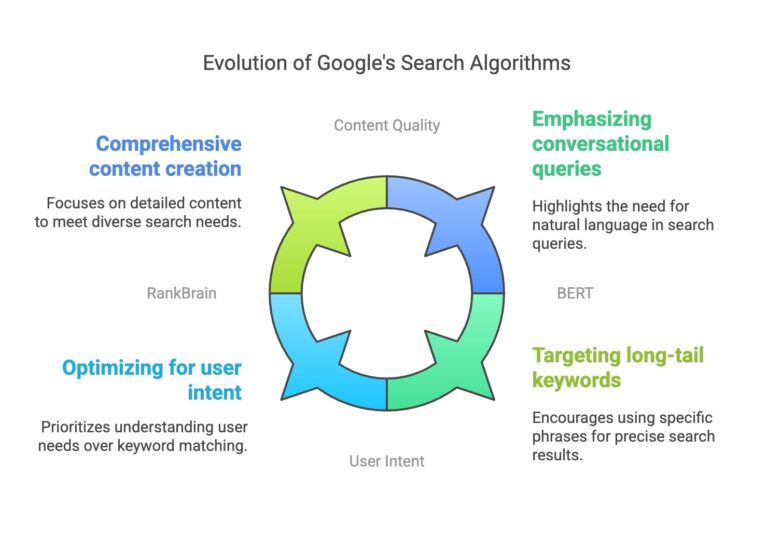
The Five Pillars of Prompt-to-Product Narrative Consistency
OpenAI’s official prompting guide emphasizes that effective Sora prompts follow a repeatable structure. Think of it like briefing a cinematographer who has never seen your storyboard: if you leave out details, they will improvise .
The proven five-part structure is:
| Component | What It Defines | Failure Mode If Missing |
|---|---|---|
| Subject + Action | Who and what with explicit timing | Characters morph, actions are vague |
| Camera + Movement | Shot type, lens, motion | Random angles, shaky footage |
| Setting + Time | Environment and temporal context | Backgrounds shift between shots |
| Lighting + Palette | Source, direction, color anchors | Inconsistent mood and exposure |
| Style + Technical | Aesthetic references, resolution | Generic “AI look” without character |
This formula accounts for what actually breaks in AI video generation . Let’s examine each pillar in detail, with before-and-after examples drawn from real Sora 2 prompting.
Pillar 1: Subject + Action with Explicit Timing
Vague descriptions are the enemy of consistency. “Person moves quickly” gives the model nothing to anchor to. The result is unpredictable motion—sometimes too fast, sometimes too slow, rarely matching your intent .
Weak prompt:
Actor walks across the room.Strong prompt:
Actor takes four steps to the window, pauses, and pulls the curtain in the final second.The specificity matters. By breaking the action into beats (“four steps,” “pauses,” “pulls the curtain in the final second”), you provide temporal anchors that the model can follow precisely . The clearer you are about the timing, the more likely the model is to execute the action exactly as you envision.
For character consistency across multiple shots, anchor your subject with three to four distinctive visual details and reuse that exact phrasing across all prompts. If your character is “a woman in a burgundy coat and gray scarf,” describe her that way every single time .
Pillar 2: Camera + Movement with Stability Cues
Camera direction and framing shape how a shot feels. A wide shot from above emphasizes space and context. A close-up at eye level focuses attention on emotion. But vague instructions like “cinematic look” leave the model guessing .
Weak prompt:
Camera shot: cinematic lookStrong prompt:
Camera shot: wide shot, low angle. Depth of field: shallow (sharp on subject, blurred background).For multiple shots in a sequence, maintain a “style spine”—a set of repeating camera choices that you carry across prompts. If you establish a 35mm lens at f/2.8 in your first shot, specify that same lens in every subsequent prompt. This creates visual continuity that the audience feels even if they cannot name it .
Camera direction examples that work:
| Orientation | Example |
|---|---|
| Framing | “wide establishing shot, eye level” |
| Tracking | “wide shot, tracking left to right with the charge” |
| Aerial | “aerial wide shot, slight downward angle” |
| Character focus | “medium close-up shot, slight angle from behind” |
Movement examples that work:
| Motion | Example |
|---|---|
| Slow tilt | “slowly tilting camera” |
| Handheld | “handheld ENG camera” |
| Dolly | “slow dolly-in from left” |
| Static | “locked tripod camera” |
Critical stability cues: Add phrases like “steady gimbal,” “stable horizon,” and “no jitter” to prevent the camera drift that plagues AI video. Each shot should have one clear camera move and one clear subject action—doing more invites failure .
Pillar 3: Lighting + Color Anchors for Seamless Edits
Light determines mood as much as action or setting. Diffuse light across the frame feels calm and neutral. A single strong source creates sharp contrast and tension. When you want to cut multiple clips together, keeping lighting logic consistent is what makes the edit seamless .
Weak prompt:
Lighting + palette: brightly lit roomStrong prompt:
Lighting + palette: soft window light with warm lamp fill, cool rim from hallway
Palette anchors: amber, cream, walnut brownDescribe both the quality of the light (soft, hard, diffused, specular) and the color anchors that reinforce it. Naming three to five colors helps keep the palette stable across shots .
Lighting recipes for different moods:
| Mood | Lighting Description |
|---|---|
| Warm/Intimate | “Soft key light from window, warm fill from fireplace, amber tones” |
| Dramatic/Tense | “Single hard light from below, cool edges, deep shadows, teal cast” |
| Documentary | “Natural available light, handheld bounce, practical sources only” |
| Nostalgic | “Golden hour backlight, subtle haze, warm saturation, soft rim” |
Pillar 4: Physics Realism with Explicit Constraints
One of Sora 2.0’s headline improvements is “more physically accurate, realistic, and more controllable” video generation, with stronger physics and world-state persistence . But the model still needs guidance.
The principle: State the object’s weight, material, contact surfaces, and expected interactions. This reduces weightless motion and implausible collisions .
Weak physics prompt:
A ball bounces.Strong physics prompt:
Rubber basketball against a glass backboard, momentum-conserving rebound, realistic friction on the rim, slight backspin, two-beat pause before impact. Follow-focus on the ball.Physics encoding checklist for your prompt :
| Property | What to Specify | Example |
|---|---|---|
| Weight | “rigid body,” “momentum-conserving” | “Heavy oak door with metal hinges” |
| Material | Surface properties | “Wet asphalt with glare” |
| Contact | Interaction description | “Non-penetrating collision, realistic friction” |
| Environment | Forces and conditions | “8-10 mph crosswind from camera left” |
When physics fails—objects morphing, limbs clipping through surfaces, implausible trajectories—tighten your constraints, reduce scene complexity, and regenerate.
Pillar 5: Audio + Dialogue Synchronization
Sora 2.0 generates synchronized audio natively, including ambient sound, sound effects, and dialogue. This is a massive upgrade from Sora 1.0’s silent clips .
For dialogue: Place spoken lines in a <dialogue> block below your prose description. Keep lines concise—one or two short sentences per character. Label speakers consistently: “Detective: ‘You’re lying.’ Suspect: ‘Or maybe I’m tired.'” This helps the model associate each line with the correct character’s gestures and expressions .
For ambient sound: Describe the sonic environment rather than micromanaging every effect. “The hum of espresso machines and the murmur of voices form the background” gives the model direction without over-constraining .
For timing: Provide a few precise cues (“door slam at 00:02; footsteps at 00:04; cheer at 00:06”) and avoid over-specifying. The model handles synchronization better when you give it rhythmic anchors rather than frame-by-frame instructions .
Audio level target for post-production: Mix to approximately -14 to -16 LUFS for web distribution .
Advanced Consistency Techniques: Beyond Basic Prompting
Once you have mastered the five-pillar structure, these advanced techniques will elevate your narrative consistency further.
The Storyboard Feature: Your Secret Weapon for Character Consistency
The most common frustration with AI video generation has been character consistency across multiple shots. “Small changes in phrasing can alter identity, pose, or the focus of the scene itself” .
The solution is the Storyboard feature. By creating all your videos using the same storyboard, your character will remain consistent . To use this effectively:
- Generate a reference image of your character (using the model’s image generation capabilities)
- Use that image as an input reference for all subsequent video generations
- The model uses the image as an anchor for the first frame, while your text prompt defines what happens next
Storyboard-first workflow :
| Step | Action |
|---|---|
| 1 | Write a beat sheet and storyboard before generating |
| 2 | Define your “style spine” (consistent camera and color language across shots) |
| 3 | Create reusable shot templates using the prompt anatomy |
| 4 | Generate 3-5 variants per shot at low resolution to probe composition |
| 5 | Select winners, then refine with precise tweaks |
| 6 | Lock seeds for consistency across retakes |
From LinkedIn creator Mike W: “Yes, character consistency is possible with Sora. What’s the secret ingredient? Storyboard!” . The storyboard acts as a shared context container, ensuring that what the model learned in shot one carries forward into shot two.
The Cameo Feature: Insert Yourself into the Story
For personalized narratives, Sora 2.0’s Cameo feature allows you to upload a short reference clip (approximately 30 seconds) and create a digital avatar that mimics your appearance and mannerisms. This avatar can then be inserted into any generated scene .
Privacy controls: You control who can use your avatar. Block commercial use, revoke access at any time, or delete data completely. Minors require parental consent .
The Iterative Workflow: Single Changes, Not Gambling
The most common mistake in AI video generation is changing too many variables at once. When a shot is close but not perfect, users often rewrite the entire prompt, losing everything that worked.
The right approach :
- Make controlled changes: one variable at a time
- Say what you are changing: “same shot, switch to 85 mm” or “same lighting, new palette: teal, sand, rust”
- When a result is close, pin it as a reference and describe only the tweak
- If a shot keeps misfiring, strip it back: freeze the camera, simplify the action, clear the background
The acceptance criteria checklist :
| Criteria | What to Check |
|---|---|
| Prompt adherence | Did we get what we asked for? |
| Motion quality | Natural camera and subject motion, no jank |
| Physical realism | Contacts, shadows, splashes, fabric behavior |
| Continuity | Coherence across shots, style spine maintained |
| Audio sync | Dialogue matched, ambient bed correct |
Technical Specifications and API Parameters
Sora 2.0 is accessible via API, with specific parameters that must be set explicitly—you cannot request them in prose .
Model Selection
model: “sora-2” or “sora-2-pro”
Resolution Support
| Model | Supported Resolutions |
|---|---|
| sora-2 | 720×1280, 1280×720 |
| sora-2-pro | 720×1280, 1280×720, 1024×1792, 1792×1024, 1080×1920, 1920×1080 |
Duration
- Supported values: “4”, “8”, “12”, “16”, “20” seconds
- Default: “4” seconds
Character References (New in March 2026)
- Upload a character once using the Characters API
- Reference up to two uploaded characters per generation
- Use the character ID returned from the API
Video Extension (March 2026)
- Extend an existing video using the full initial clip as context
- Not just the last frame—the model understands the entire preceding narrative
Batch API
- Run asynchronous video generation jobs for larger production workflows
Post-Production: The Final Polish
Even the best Sora 2.0 generation benefits from finishing work in your video editor .
Post-production checklist:
| Step | Tool/Technique | Purpose |
|---|---|---|
| Stabilize | Warp Stabilizer (Premiere) or Stabilizer (Resolve) | Fix minor camera shake |
| Deflicker | Deflicker filter | Remove lighting pulses between frames |
| Color grade | Contrast work, color matching | Unify shots, protect highlights |
| Audio mix | Normalize to -14 to -16 LUFS | Consistent loudness for web |
| Export | H.264, 24-60 fps | Match source frame rate |
Provenance and release :
- Maintain embedded metadata (C2PA when available)
- Respect visible watermark policies
- Retain consent documentation for any cameo avatars
Troubleshooting Consistency Failures
Here are the most common narrative consistency failures and their fixes.
| Problem | Likely Cause | Solution |
|---|---|---|
| Character appearance changes between shots | No visual anchor | Use Storyboard with reference image; reuse exact character descriptions |
| Lighting jumps between cuts | Inconsistent lighting language | Specify “same lighting” and reuse palette anchors |
| Camera feels chaotic | Too many movement verbs | Reduce to one camera move per shot; add “steady gimbal” |
| Physics look wrong (floating, clipping) | Missing material/force cues | Encode weight, material, contact surfaces explicitly |
| Lip-sync drifts | Dialogue too long | Shorten to one sentence; use <dialogue> block |
| Objects teleport across cuts | Lost spatial context | Use storyboard; specify “object permanence maintained” |
| Color palette shifts | No color anchors | Name 3-5 colors explicitly: “amber, cream, walnut brown” |
When issues persist, back up one layer at a time: first simplify camera, then simplify physics, then reintroduce detail .
From Clips to Cinema: The Road Ahead
Sora 2.0 represents what OpenAI calls a “GPT-3.5 moment” for video. It does not reinvent the wheel—instead, it polishes existing parts: better memory for coherence, human feedback for control, and audio integration for usability .
The difference between burning credits on failures and generating reliably is not luck. It is prompting with Sora 2.0’s actual capabilities in mind. The model now understands long-context narrative memory. It can maintain character consistency through the Storyboard feature. It speaks the language of cinematography natively. It can generate synchronized dialogue and ambient sound.
But it still needs a director. That is you.
Frequently Asked Questions
Q: Can Sora 2.0 really maintain character consistency across multiple shots?
A: Yes. Using the Storyboard feature with consistent character descriptions and reference images, community creators have demonstrated reliable character consistency across multiple generations .
Q: What is the maximum video length in Sora 2.0?
A: The API supports up to 20 seconds per generation . For longer sequences, use the video extension endpoint or stitch multiple clips in post-production.
Q: Does Sora 2.0 generate audio automatically?
A: Yes. Sora 2.0 generates synchronized audio natively, including ambient sound, sound effects, and dialogue .
Q: Do I need to be a professional cinematographer to get good results?
A: No. The prompting guide provides templates and examples for common scenarios. However, thinking like a director—planning shots, specifying camera moves, describing lighting—dramatically improves results.
Q: Can I use my own images as references for character consistency?
A: Yes. The API supports image input for composition and style control. Upload an image as the input_reference parameter, and the model uses it as an anchor for the first frame .