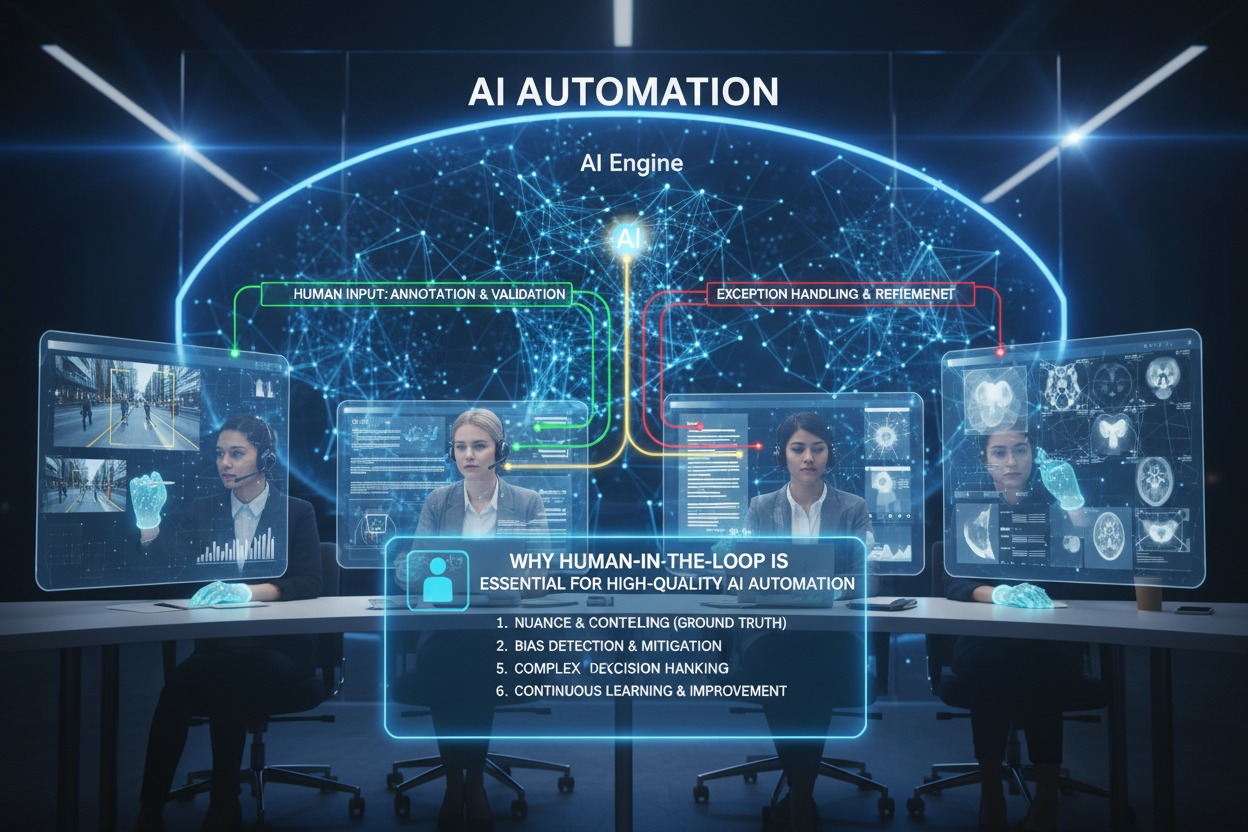
Why “Human-in-the-Loop” is Essential for High-Quality AI Automation
Why “Human-in-the-Loop” is Essential for High-Quality AI Automation, In the rush to automate everything, a crucial truth has emerged: AI systems, for all their remarkable capabilities, are not reliable enough to be left unsupervised. The year 2026 has made this painfully clear. After a decade of breakneck AI development, organizations are discovering that the bottleneck to scaling isn’t model capability—it’s trust .
This is where Human-in-the-Loop (HITL) comes in. Far from being a temporary crutch or a sign of automation failure, HITL has emerged as the essential governance framework for high-quality AI. It is the mechanism that transforms probabilistic, sometimes-unreliable models into dependable, auditable systems that businesses can actually use.
As one industry expert noted, “AI is a powerful accelerator, but most teams are still doing the hard work of making its output accurate and complete enough for real-world use. The real opportunity isn’t just adopting AI—it’s building the oversight habits that keep quality high as speed increases” .
This guide explains why HITL is non-negotiable for high-quality AI automation, how it works in practice across different industries, and how to implement it effectively in your organization.
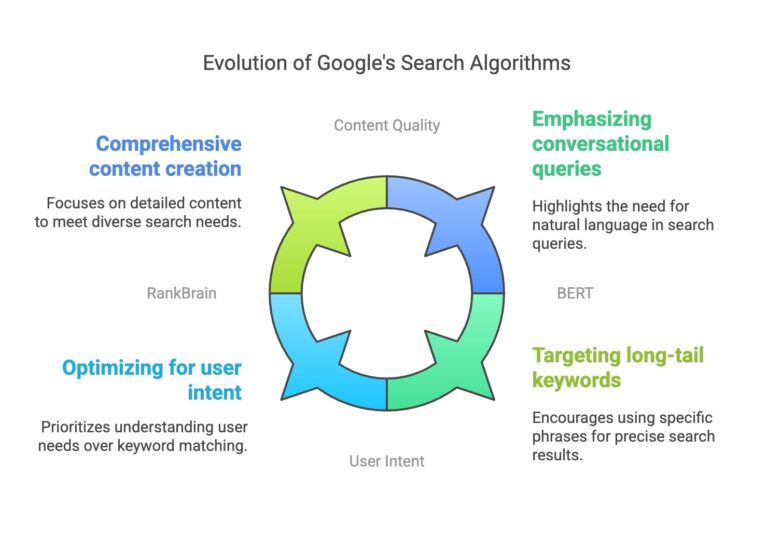
What Is Human-in-the-Loop? A Clear Definition
Human-in-the-Loop (HITL) is an architecture that strategically integrates human judgment into automated systems, creating a hybrid approach that leverages both AI efficiency and human expertise . It is not a simple “approval button” tacked on at the end of a process. Instead, it is a design philosophy that positions humans and machines as complementary forces, each doing what they do best.
The Core Distinction: Two Models of Oversight
Not all HITL is created equal. The level of human involvement should match the risk and complexity of the task :
| Model | Description | Best For | Example |
|---|---|---|---|
| Human-in-the-Loop (HITL) | Every output passes through human review before release | High-stakes decisions (compliance, legal, clinical) | Contract redlining, diagnostic validation |
| Human-on-the-Loop (HOTL) | Humans audit samples, review flagged outputs, intervene when something breaks pattern | High-volume, moderate-risk operations | Content moderation, document processing |
The key insight is that HITL isn’t about rejecting automation—it’s about governing it. As one expert explains, “Human-in-the-loop is an adoption and trust-building mechanism, where AI starts by gathering context and recommending actions before graduating to higher-impact execution” .
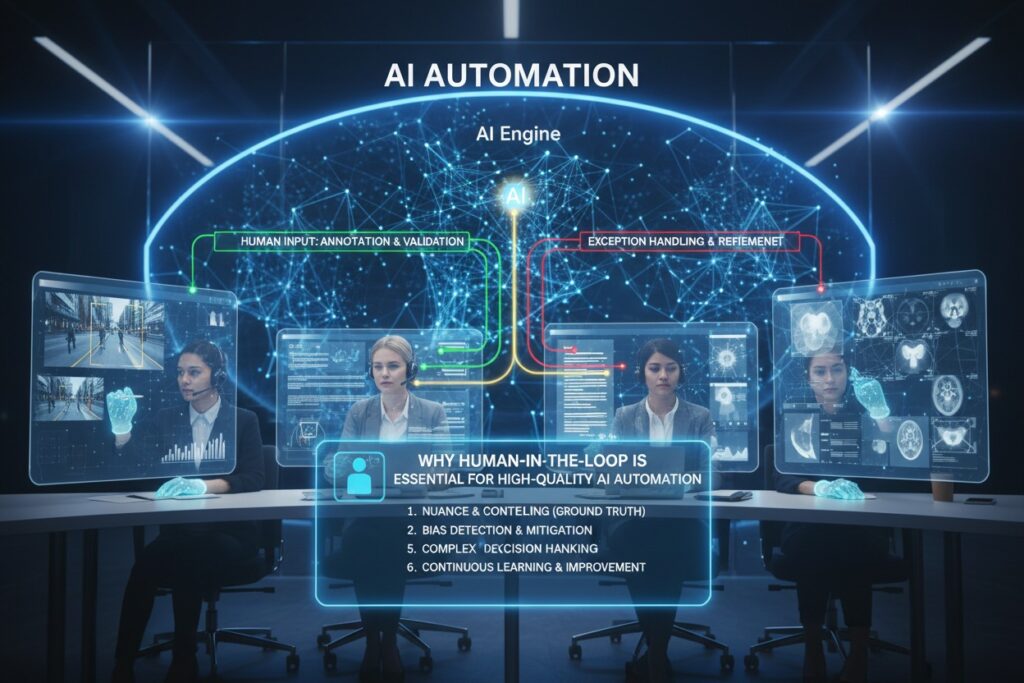
The Trust Gap: Why AI Can’t Run Alone
The most compelling argument for HITL comes from the people using AI every day. A comprehensive January 2026 survey of 1,000 U.S. adults who use AI at work found striking levels of distrust in autonomous AI .
The Numbers Tell a Clear Story:
- Only 17% of respondents believe AI can run on its own with minimal human involvement
- 70% say reliability requires a human safety net—either “light review” (35%) or “dedicated oversight” (35%)
- Nearly two-thirds (64%) expect the need for human review to increase in the future
Why is trust so low? Because AI’s failure modes are uniquely frustrating. The survey revealed exactly what goes wrong :
- 42% say AI left out important details or context
- 32% say it caused extra work to fix or redo
- 31% say it “sounded confident but was wrong”
This last point is critical: when a human is unsure, they hedge. AI, by contrast, is often confidently incorrect—making its errors harder to spot and more dangerous to ignore.
The consequences aren’t abstract. 60% of respondents said they have personally been involved in AI negatively affecting outcomes, including customer frustration, complaints, and in 11% of cases, lost revenue or churn .
The “Shadow AI” Problem
When official enterprise AI systems produce outputs employees can’t trust, those employees don’t stop using AI—they just route around the approved systems. They use personal ChatGPT subscriptions and external copilots to self-validate, introducing obvious security and compliance risks .
This is the “shadow AI gap”—the distance between what employees need from AI outputs and what approved systems can reliably provide. It’s not an adoption failure; it’s a symptom of low-trust outputs.
The Four Core HITL Patterns
Different situations call for different types of human involvement. The AWS Generative AI Atlas outlines four fundamental HITL patterns that serve different scenarios :
1. Approval-Based Pattern
This pattern focuses on binary decisions where reviewers either approve or reject AI-generated outputs without modification.
How it works: The AI system evaluates responses against confidence thresholds and business rules, routing uncertain outputs to human reviewers. Approved responses proceed directly to users; rejected ones trigger fallback mechanisms.
Best for: High-stakes scenarios requiring definitive judgments—loan approvals, compliance reviews, where the decision framework is clear and binary outcomes are sufficient.
2. Review and Edit Pattern
This pattern enables reviewers to actively modify AI-generated content before it reaches users.
How it works: Reviewers receive AI outputs along with relevant context and source materials, using editing interfaces tailored to the content type. The system tracks modifications to identify improvement patterns.
Best for: Content creation workflows—marketing materials, documentation, code generation—where nuanced quality matters and human expertise adds significant value.
3. Escalation-Based Pattern
This pattern provides dynamic handover from AI to human experts during active interactions.
How it works: AI systems initially handle interactions independently but escalate when specific conditions are met: user requests human assistance, negative sentiment is detected, conversations enter complex territory, or multiple clarification attempts fail.
Best for: Customer support and conversational applications, where AI efficiency for routine interactions combines with human expertise when needed.
4. Feedback Loop Pattern
This pattern creates iterative improvement cycles where users interact with AI, review outputs, and provide feedback that refines results in real-time.
How it works: Feedback mechanisms range from simple binary responses to rich interactions like inline editing and dimensional ratings. The system incorporates both explicit feedback and implicit signals like usage patterns.
Best for: Collaborative scenarios—code generation, document creation—where users and AI work together through multiple iterations.
Industry Deep Dives: HITL in Action
Healthcare: Where Errors Have Human Consequences
Healthcare represents the most compelling case for HITL—and the most sophisticated implementation. The stakes couldn’t be higher: an AI error isn’t an inconvenience; it could be a life.
Case Study: The “Maria” Clinical AI Platform
A peer-reviewed case study from January 2026 describes “Maria,” a production-grade AI system in primary healthcare that demonstrates how HITL should work in high-stakes domains . The researchers’ central hypothesis was that “trustworthy clinical AI is achieved through the holistic integration of four foundational engineering pillars.”
The key innovation? HITL isn’t a safety check bolted on at the end—it’s integrated as a “critical, event-driven data source for continuous improvement.” Every human intervention becomes structured data that makes the system better .
Case Study: IKS Health and Certilytics Partnership
A major healthcare partnership announced in March 2026 explicitly built HITL into their agentic AI platform. The collaboration aims to bridge the payer-provider gap by turning predictive insights into “safe, coordinated clinical actions” .
According to IKS Health’s founder and Global CEO, “For AI to be truly effective in healthcare, it must be responsible… our proven human-in-the-loop model serves as the ultimate safeguard for clinical and administrative accuracy” .
The results are measurable: in prior authorization workflows, more than 70% are handled autonomously, with the remainder escalated to humans for judgment .
Oil and Gas: HITL at Milliseconds
The energy sector is discovering that traditional HITL models aren’t sufficient for high-velocity, safety-critical operations .
The Problem with Traditional HITL
In oil and gas operations, AI outputs already drive automated adjustments—pump settings, compressor controls, emissions tuning—within pre-approved guardrails. In environments where decisions unfold in milliseconds (pressure spikes offshore, corrosion hotspots), the idea that a field engineer will manually validate every output is unrealistic .
The Evolution: Governance Outside the Loop
Major operators are moving toward a new paradigm. Companies like ADNOC, Saudi Aramco, BP, and Shell are shifting human oversight from real-time intervention to system-level governance :
- Design and Constraints: Humans define where AI can act autonomously and what safety boundaries apply—embedded directly into the software architecture
- Explainability and Traceability: AI decisions must be auditable, with trace logs and verifiable data sources
- Clear Accountability: Responsibility shared across data teams, model developers, system designers, and operations
- Governance Outside the Loop: Humans oversee system health, change management, audits, and scenario testing—not individual micro-decisions
This evolution doesn’t reduce human authority—it relocates it to where it is most effective.
Defense: Where HITL Is Doctrine
In military contexts, HITL isn’t just best practice—it’s official doctrine. Organizations like the U.S. Department of Defense and NATO have issued formal guidance stating that AI systems must be traceable, governable, transparent, and subject to human control .
Why HITL Matters in Defense
Even the most advanced AI can’t replace human judgment in mission-critical scenarios :
- Air-to-ground decisions: AI can interpret terrain and threat data, but only a human can evaluate civilian risk, political implications, and rules-of-engagement compliance
- Ground robotics: An autonomous robot may navigate on its own, but a human must take control when terrain becomes unpredictable, civilians enter the area, or malfunctions occur
- Contested environments: Autonomy is most vulnerable when the environment becomes least predictable—in GPS-denied or electronic warfare conditions, human assessment is critical
The principle is clear: autonomy may evolve, but human authority—and human responsibility—must remain central.
Enterprise: Designing HITL from the Ground Up
At Rolls-Royce, practitioners have learned that HITL functions not as a design feature but as a “fundamental design principle” .
Two Dimensions of the Loop
The Rolls-Royce approach reveals that HITL operates across two dimensions :
- Oversight and accountability: The well-recognized need for humans to review, interpret, and accept or reject AI outputs
- Cooperative and participatory design: Involving humans not only as validators but as co-creators who define requirements, validate data, shape workflows, and test prototypes
One telling moment came when a colleague, after seeing the prototype and understanding the design choices, said: “Well then, I can trust this thing.” Trust wasn’t about the technology—it was about the collaborative design process .
The Business Case: HITL Drives ROI
HITL isn’t just about safety—it’s about economics. Organizations that implement HITL effectively achieve better outcomes, faster.
HITL Enables High-Value Automation
The IKS Health partnership demonstrates this clearly. By implementing HITL, they achieved:
- >70% of prior authorization workflows handled autonomously
- Reduced burden for providers
- Faster care for patients
Without HITL, that level of automation would be impossible—the risk of error would simply be too high.
HITL Creates a Learning System
Every human correction is data. When captured systematically, these corrections become the highest-quality training signal for continuous improvement .
The alternative is worse: organizations can pay for AI, pay for human reviewers, but fail to capture why corrections were made—losing the training signal entirely.
The Cost of Not Implementing HITL
The survey data reveals hidden costs of insufficient oversight:
- 46% say fixing AI output takes about the same time as doing it manually
- 11% say it takes more time
- 19% say AI made a customer situation worse
In other words, AI without HITL isn’t just risky—it can be more expensive than doing the work manually.
How to Implement HITL: A Practical Framework
Step 1: Start with Clear Risk Assessment
Identify scenarios where human oversight delivers the most value. Focus initial efforts on :
- High-risk interactions where AI mistakes have significant consequences
- Complex edge cases that challenge current AI capabilities
- Regulated environments where compliance requires human verification
Map different interaction types to appropriate HITL patterns based on risk levels and resource constraints.
Step 2: Design Rubrics Before Building Anything
Most teams underestimate rubric design—but it’s the control surface for your entire validation system. When the rubric is weak, everything downstream becomes inconsistent .
A Seven-Step Rubric Development Process:
- Define the decision the output supports (not just “is the answer good?”)
- Separate correctness from usefulness—factual accuracy vs. workflow fit
- Declare non-negotiables (in high-risk contexts, hallucination tolerance is zero)
- Create severity tiers: critical errors (unsafe, non-compliant), major errors (misleading, causes rework), minor errors (stylistic)
- Include counterexamples—concrete cases of what fails and why
- Pilot with disagreement tracking
- Version the rubric like code
The step most teams skip is counterexamples. Without them, reviewers default to personal judgment—and consistency drops immediately.
Step 3: Use LLM-as-a-Judge for Triage, Not Truth
LLM-as-a-Judge systems can function as a pre-screening layer, a consistency layer, an uncertainty detector, and a routing mechanism for human review. But they should route attention, not declare truth .

What makes an LLM judge reliable:
- Rubric grounding: It must score against explicit criteria, not holistic “overall quality”
- Calibration: Compare judge scores to what human domain specialists say
- Bias checks: Watch for position effects, verbosity preferences, self-enhancement
- Disagreement routing: When uncertain or when multiple judges disagree, escalate to human
- Drift monitoring: As workflows shift, judge behavior shifts with them
For high-risk flows, use disagreement checks between multiple judges—treating judge disagreement itself as a signal for escalation.
Step 4: Design for User Experience
Implement HITL patterns that align with user expectations and workflow requirements :
- Real-time applications need seamless escalation mechanisms that preserve conversation context
- Asynchronous processes can benefit from more thorough review cycles
- Communicate the value proposition clearly to users—why human oversight improves outcomes
Transparent communication about review processes builds user confidence and acceptance of any associated delays.
Step 5: Build Measurement and Improvement Capabilities
Establish metrics that capture both operational efficiency and quality outcomes :
| Metric | What It Measures |
|---|---|
| Intervention rates | How often humans need to override AI |
| Approval patterns | Which outputs pass or fail consistently |
| User satisfaction | Trust and perceived reliability |
| System improvement trends | Is the AI getting better over time? |
Use HITL data to drive continuous improvement, identifying opportunities to reduce human intervention needs while maintaining quality standards.
The Future: HITL as a Strategic Capability
As AI continues to advance, the role of HITL is evolving—but not disappearing. The question is no longer whether humans should be involved, but how and where.
From “In the Loop” to “On the Loop”
In high-velocity environments (oil and gas, defense, autonomous vehicles), the traditional model of moment-to-moment human review is becoming impossible. The future is “human-on-the-loop”—humans overseeing system health, change management, and scenario testing, not individual micro-decisions .
HITL as a Learning Mechanism
The most sophisticated organizations treat HITL not as a cost center but as a strategic asset. Every human correction is a training signal. Organizations that capture these signals systematically will have an unassailable advantage over those that don’t .
The Regulatory Imperative
Regulators are catching up. The EU AI Act, emerging frameworks in the UK and US, and industry standards all point toward mandatory human oversight for high-risk AI applications. Organizations that build HITL into their architecture now will be far better positioned as these standards evolve .
Conclusion
The evidence is overwhelming. AI systems in 2026 are powerful but not reliable. They hallucinate, miss context, and confidently produce errors. Without human oversight, they damage customer relationships, waste time, and create unacceptable risk in high-stakes domains.
Human-in-the-Loop is not a temporary crutch or a sign of automation failure. It is the essential governance framework that transforms probabilistic, sometimes-unreliable models into dependable, auditable systems. It is the mechanism that enables high-value automation while maintaining quality, accountability, and trust.
The organizations that succeed with AI will not be those that eliminate humans from the loop—they will be those that design the loop thoughtfully, position humans where they add the most value, and build systems that learn from every interaction.
As the Rolls-Royce practitioner observed, “Designing AI is no longer just a technical task—it is a deeply human business” . The loop isn’t a step to be automated away. It’s a full circle that keeps humans where they belong: in control.