AI Voice Synthesis 2026: Best Tools for Natural, Multilingual Narration
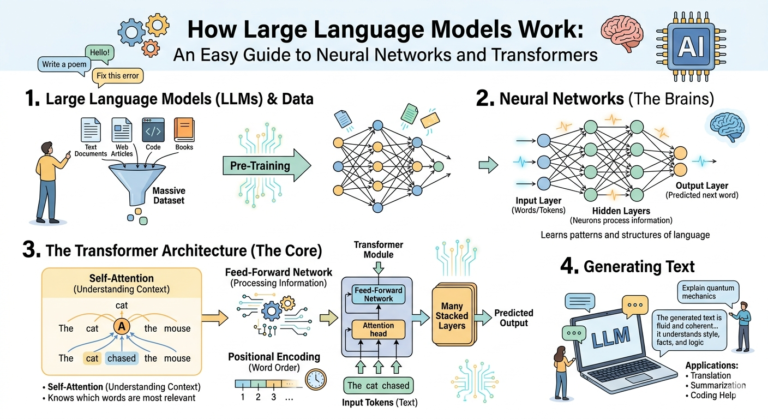
AI Voice Synthesis 2026: Best Tools for Natural, Multilingual Narration, The gap between synthetic and human speech has effectively closed. In 2026, AI voice generators no longer sound like robotic text-to-speech systems—they capture breath, pacing, emphasis, and the subtle variations that make human conversation feel alive. Whether you’re producing multilingual podcasts, dubbing video content, building voice agents, or narrating audiobooks, today’s tools offer unprecedented naturalism and control.
This guide covers the best AI voice synthesis tools of 2026, organized by use case—from premium production platforms to open-source models and real-time streaming solutions. I’ve included pricing, language support, and practical guidance to help you choose the right tool for your specific needs.
What Makes a Great AI Voice Generator in 2026?
Before diving into specific tools, it’s worth understanding the criteria that separate exceptional voice synthesis from merely adequate output.
Voice Naturalness and Expressiveness: The best models handle prosody—the rhythm, stress, and intonation of speech—with human-like fluidity. They can convey excitement, hesitation, warmth, or authority without sounding like they’re reading from a script.
Language and Accent Support: True multilingual capability means native pronunciation across languages, not just phonetic approximation. Top models handle tonal languages like Mandarin and Cantonese, maintain accent consistency across code-switching, and support regional dialects.
Voice Cloning Accuracy: The ability to replicate a specific voice from a short audio sample (often 5-30 seconds) while preserving unique characteristics like pitch, pace, and timbre.
Emotion and Style Control: Granular control over delivery—adjusting happiness, sadness, anger, whisper, or authoritative tones—either through tags, prompts, or dedicated sliders.
Latency and Streaming: For real-time applications like voice assistants or live narration, sub-second latency matters. Some models now achieve 150ms streaming with minimal quality degradation.
Cost Structure: Pay-per-character or pay-per-minute pricing varies widely, from budget-friendly options at $0.02 per 1,000 characters to premium services at $0.10 per 1,000 characters.

Premium Production Tools
These tools offer the highest quality output, extensive voice libraries, and production-ready features—ideal for professional content creators, marketing teams, and media production.
MiniMax Speech 02 HD
Best for: Production teams needing 30+ languages, 300+ voices, and granular emotion control
MiniMax Speech 02 HD is arguably the most feature-complete voice system available in 2026. It offers over 300 pre-built voices across 30+ languages, with native pronunciation that handles tonal languages like Chinese exceptionally well.
The emotion control system isn’t a gimmick—switching between “happy,” “sad,” and “neutral” produces audibly different intonation patterns, not just volume changes. You can also insert interjection tags and custom pause markers for precise timing control. Voice cloning is available for $1.50 per clone, with the platform retaining the speaker’s unique characteristics across outputs.
Pricing: $0.10 per 1,000 characters (approximately one minute of speech)
Languages: 30+ including Chinese, English, Japanese, Korean, Spanish, French, German
Best for: Audiobooks, multilingual marketing content, dubbing, character-driven narration
ElevenLabs Turbo v2.5
Best for: Premium voice quality with low latency and streaming
ElevenLabs has long been the benchmark for human-like voice synthesis, and Turbo v2.5 maintains that reputation in 2026. The model excels at producing voices that sound genuinely alive—with natural breath timing, appropriate emphasis, and conversational cadence that avoids the “uncanny valley”.
The platform’s strength lies in its emotional range and the ability to generate consistent character voices across long-form content. It supports streaming generation, making it suitable for real-time applications alongside pre-recorded production.
Pricing: $0.05 per 1,000 characters
Languages: 29+ with ongoing expansion
Best for: Professional voiceover, character voices, real-time voice agents, marketing content
fal.ai Platform
Best for: Teams and developers who need access to every top TTS model through a single API
Rather than choosing one tool, many developers now work through fal.ai—a unified platform that provides API access to every major voice model (MiniMax, ElevenLabs, Kokoro, Dia, and more) through a single integration.
The platform’s custom inference engine delivers 5-10 second cold starts (versus 20-60+ seconds on competitors) through optimized CUDA kernels. Pay-per-use pricing means you can use Kokoro for cost-efficient drafts and switch to ElevenLabs or MiniMax for final production without changing your integration code.
Pricing: Pay-per-use starting at $0.02/1K characters (Kokoro) up to $0.10/1K characters (MiniMax)
Languages: Varies by model; platform aggregates 600+ models total
Best for: Development teams, applications requiring multiple voice models, production-scale deployments
Open-Source and Self-Hosted Models
For organizations with privacy requirements, technical teams, or budget constraints, open-source models offer compelling alternatives to commercial APIs.
Fish Speech V1.5
Best for: Premium multilingual quality with extensive training data
Fish Speech V1.5 leads the open-source pack with an innovative DualAR architecture (dual autoregressive transformer design). It’s trained on over 300,000 hours of English and Chinese audio and 100,000 hours of Japanese—far more than most commercial competitors.
In TTS Arena evaluations, it achieved an exceptional ELO score of 1339 with a 3.5% word error rate (WER) for English and 1.2% character error rate (CER)—numbers that rival premium commercial offerings. The model supports English, Chinese, Japanese, and multiple other languages with native pronunciation.
Pricing: $15 per million UTF-8 bytes on SiliconFlow; free for self-hosting (requires technical setup)
Languages: English, Chinese (Mandarin), Japanese, plus additional language support
Best for: Production-quality multilingual content, developers with GPU access, privacy-conscious organizations
CosyVoice2-0.5B
Best for: Real-time streaming with ultra-low latency (150ms)
Developed by FunAudioLLM, CosyVoice2 is a streaming speech synthesis model built on a unified streaming/non-streaming framework. In streaming mode, it achieves just 150 milliseconds of latency while maintaining quality nearly identical to non-streaming mode.
Compared to version 1.0, pronunciation errors dropped by 30-50% and MOS scores improved from 5.4 to 5.53. The model provides fine-grained control over emotion and dialect, supporting Chinese (including regional dialects like Cantonese, Sichuanese, and Shanghainese), English, Japanese, Korean, and cross-lingual scenarios.
Pricing: $7.15 per million UTF-8 bytes on SiliconFlow
Languages: Chinese dialects, English, Japanese, Korean, cross-lingual
Best for: Live voice assistants, real-time translation, interactive applications, podcast recording

IndexTTS-2
Best for: Precise duration control and independent voice/emotion management
IndexTTS-2 solves one of the most challenging problems in TTS: precise timing control. For applications like video dubbing where audio must match visual timing exactly, this capability is essential.
The model achieves true decoupling between emotional expression and speaker identity—you can control timbre and emotion through separate prompts. This means you can generate the same emotional delivery across different voices, or apply different emotions to the same voice, with remarkable consistency.
The architecture integrates GPT latent representations with a three-stage training paradigm, and a soft instruction mechanism (fine-tuned on Qwen3) enables text-based emotional guidance.
Pricing: $7.15 per million UTF-8 bytes (input and output are both billed)
Languages: Multiple (specific coverage expanding)
Best for: Video dubbing, animation, timed narration, educational content with synchronized visuals
NVIDIA MagpieTTS Multilingual 357M
Best for: Enterprise deployment with NVIDIA infrastructure
NVIDIA’s MagpieTTS is a 357-million-parameter model that generates speech in five English voices (Sofia, Aria, Jason, Leo, John Van Stan), each capable of speaking nine languages: English, Spanish, German, French, Vietnamese, Italian, Mandarin, Hindi, and Japanese.
The model uses a transformer encoder-decoder architecture with multi-codebook prediction (eight codebooks) and supports classifier-free guidance (CFG) for improved alignment. It’s available through NVIDIA’s NeMo Framework and is ready for commercial use.
The enterprise offering (MagpieTTS NIM) adds additional native voices, emotional speech capabilities, and optimized batch/latency inference pipelines.
Pricing: Open source (self-hosted) or through NVIDIA enterprise licensing
Languages: 9 with each voice (English, Spanish, German, French, Vietnamese, Italian, Mandarin, Hindi, Japanese)
Best for: Enterprise deployments on NVIDIA GPU infrastructure, voice agents, offline speech generation
Emerging Innovations
Smallest.ai Lightning V3
Best for: Conversational voice agents with state-of-the-art intonation
Released in March 2026, Lightning V3 claims to outperform OpenAI, Cartesia, and ElevenLabs on conversational voice benchmarks. It achieves a 3.89 Mean Opinion Score (MOS) in conversational evaluations, with leading scores for intonation (3.33) and prosody (3.07)—two factors critical for natural dialogue.
The model is specifically optimized for how voice systems actually run in production: generating speech in chunks, without full context, and adapting as conversations evolve. It supports 15 languages with automatic detection and mid-sentence switching, and can clone a voice from just 5-15 seconds of audio.
Pricing: Pay-as-you-go, no seat licenses or minimum usage
Languages: 15 with auto-detection and mid-sentence switching
Best for: Voice agents, contact centers, conversational AI, interactive applications
ByteDance Seed Speech 2.0
Best for: Unified speech generation and recognition with multimodal understanding
ByteDance’s Seed Speech 2.0 combines expressive text-to-speech (TTS 2.0) with accurate speech recognition (ASR 2.0) in a unified platform. The TTS component uses a query–response synthesis mechanism that interprets conversational context to generate appropriate tone, rhythm, and pauses.
The platform supports multilingual recognition across 51 languages with speaker emotion detection. It also improves far-field recognition for device-based applications, reducing error rates by approximately 50% for smart speakers and wearables.
For educational and technical content, TTS 2.0 achieves around 90% accuracy reading complex formulas and symbols across mathematics and science.
Pricing: Contact BytePlus for enterprise pricing
Languages: 51 for recognition; TTS coverage expanding
Best for: Multilingual voice agents, educational content, device-based voice interaction, comprehensive speech applications
MOSS-VoiceGenerator
Best for: Voice design from natural language descriptions
Released in March 2026, MOSS-VoiceGenerator is an open-source instruction-driven model that creates new timbres directly from free-form text descriptions—no reference audio required.
Users can describe the voice they want (“a warm, elderly British narrator with a slight rasp” or “an energetic young American podcaster with enthusiasm”) and the model generates appropriate timbres. It’s trained on large-scale expressive speech from cinematic content, prioritizing the lived-in, natural qualities often missing from studio-recorded datasets.
Pricing: Open source
Languages: Primarily English with expanding multilingual support
Best for: Game dubbing, storytelling, role-play agents, character voice creation
Comparison Table: Top AI Voice Tools in 2026
| Tool | Best For | Pricing (per 1K chars) | Languages | Key Strength |
|---|---|---|---|---|
| MiniMax Speech 02 HD | Production teams | $0.10 | 30+ | 300+ voices + emotion control |
| ElevenLabs Turbo v2.5 | Premium voiceover | $0.05 | 29+ | Human-grade naturalness |
| fal.ai | API unification | $0.02-0.10 | Varies | Single API for all models |
| Fish Speech V1.5 | Open-source multilingual | $0.015 (platform) | 5+ | 1339 ELO, 3.5% WER |
| CosyVoice2-0.5B | Real-time streaming | $0.007 | Asian + English | 150ms latency |
| IndexTTS-2 | Duration control | $0.007 | Multiple | Independent voice/emotion |
| Lightning V3 | Voice agents | Pay-as-you-go | 15 | 3.89 MOS, 3.33 intonation |
| Seed Speech 2.0 | Unified speech AI | Enterprise | 51 recognition | TTS + ASR + multimodal |
| MOSS-VoiceGenerator | Text-prompt voice design | Open source | English | No reference audio needed |
| NVIDIA MagpieTTS | Enterprise GPU | Open source | 9 per voice | NVIDIA infrastructure ready |
How to Choose the Right Tool
For professional content production (audiobooks, marketing, dubbing): MiniMax Speech 02 HD or ElevenLabs Turbo v2.5 deliver the highest quality with extensive voice libraries and emotional range.
For real-time applications (voice assistants, live streaming): CosyVoice2-0.5B offers 150ms latency with minimal quality compromise, while Lightning V3 excels in conversational coherence.
For multilingual requirements: Fish Speech V1.5 leads open-source options with massive training datasets across English, Chinese, and Japanese. MiniMax offers the broadest commercial language coverage at 30+ languages.
For video dubbing and timed narration: IndexTTS-2 provides precise duration control unmatched by other models.
For privacy-conscious deployments: Open-source models (Fish Speech, CosyVoice, IndexTTS) can be self-hosted, ensuring no data leaves your infrastructure. NVIDIA MagpieTTS is designed for enterprise on-premises deployment.
For development teams: fal.ai provides a single API to access all major models, enabling you to switch between providers without code changes. This is ideal for A/B testing and production scaling.
For experimental voice design: MOSS-VoiceGenerator allows creating new voices from text descriptions alone—perfect for game characters, storytelling, and creative applications where reference audio isn’t available.
The Bottom Line
AI voice synthesis in 2026 offers something for every use case and budget. The gap between synthetic and human speech has effectively closed—the challenge is no longer finding a voice that sounds human, but finding the right tool for your specific workflow.
For most professional creators, ElevenLabs and MiniMax deliver the highest quality with minimal technical overhead. For developers building voice applications, fal.ai’s unified API or open-source models like CosyVoice provide the flexibility and scalability needed for production deployment. For experimental projects and creative voice design, emerging tools like MOSS-VoiceGenerator open entirely new possibilities.
Whichever tool you choose, one thing is clear: the era of robotic text-to-speech is over. The voices we generate today can inform, persuade, and move audiences with the same nuance as human narrators. The only limit is how creatively you choose to use them.